
The idea of open, multi-engine data lakehouses is gaining momentum in the data industry. Here is what has happened in the last six months alone.
-
Last week, the data community was abuzz when AWS announced Iceberg-based S3 Tables at this year's re:Invent.
-
In October, Snowflake launched a managed service for Iceberg metadata catalogs called Open Catalog.
-
A month before, in September, at the first Small Data conference in San Francisco, Wes McKinney re-introduced the idea of Composable Data Systems built on the foundation of open storage.
-
Earlier this year, in June, we had Databricks wedding-crashing Snowflake's Summit by buying Tabular for 2 trillion dollars (ed: we make no guarantees about the correctness of the amount) when Snowflake was announcing the donation of the Polaris Iceberg catalog to open source.
-
A week later, Motherduck photo-bombed Databrick's own Summit by sending a platoon of duck-costumed people to Moscone Center, carrying signs including "Big Data is Dead" and "Single Machines Rule."
There is clearly something big brewing in the data management and processing space, and perhaps we are witnessing the beginning of a re-platforming of the entire data stack. However, as is often the case in our industry, there is also a lot of vendor vaporware and FUD. We decided to check what works today and what doesn't by building a realistic, open, multi-engine-capable data lakehouse using just a minimal number of components.
All six posts of this 6-part series are now available:
Part 1: Building Open, Multi-Engine Lakehouse with S3 and Python
Part 2: How Iceberg stores table data and metadata
Part 3: Picking Snowflake Open Catalog as a managed Iceberg catalog
Part 4: How to create S3 buckets to store your lakehouse
Part 5: How to set up a managed Iceberg catalog using Snowflake Open Catalog
Part 6: How to write Iceberg tables using PyArrow and analyze them using Polars
But first, let's review what we are talking about here.
What is a data lakehouse, or an open lakehouse?
If you haven't heard of data lakehouses before, think of a data warehouse where tables are stored across many files in public cloud storage services (e.g., Amazon's S3), with the crucial metadata about these tables (for example, which files contain the table's data) stored near the data in the same cloud bucket.
However, storing tabular data in files on S3 does not make this collection of files an open lakehouse.
A lakehouse becomes "open" when two or more "engines", for example, Spark, Snowflake, or even one of those newer Python frameworks like Polars, can read and write from these tables concurrently as if data was stored in their native storage (e.g., FDN files in Snowflake). Two things enable this openness:
-
An open table format like Apache Iceberg, and
-
A catalog service that coordinates changes to the table metadata.
The following diagram illustrates an open data lakehouse architecture.
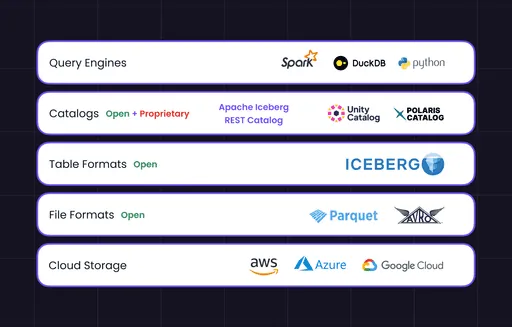
If you are in the business of using or building data platforms, you have probably encountered data platform teams that use Spark and Snowflake simultaneously but for different workloads (the typical split is Spark for ML workloads and Snowflake for everyone who prefers SQL).
These teams are forced to build expensive ETL processes that move data from one system to the other. Many customers think this is a waste of their money and time, which led to the development of technologies such as Apache Iceberg (originally developed at Netflix).
Now that we have covered the basics, let's set our goals for our project.
-
Realistic data storage setup: while we all like developing on our overpowered Macbooks, the lakehouse must live in cloud storage, not on our local disks.
-
Python-first: DuckDB and Spark are great, but Python ain't shabby either. There are tons of examples out there showing how to query or create Iceberg tables with DuckDB or Spark. But how about popular Python libraries like Polars?
-
Open and multi-engine: we want to be able to use multiple "engines" to read and write our data concurrently.
Cloud Data Storage
The first goal is the most obvious, and we will show you how to create an S3 storage bucket in a companion post (but you could also use Azure or GCP storage). The most challenging part of the S3 bucket setup is data access permissions and the policies you will use to manage them. Otherwise, this is pretty straightforward.
Python-first
For the second goal, the Python purism one, this is where things start getting interesting. If you want a Python data app to create Iceberg tables without using Spark, you must import the PyIceberg library and use it as the interface to Iceberg. If you then want to query Iceberg tables and do complex transformations and aggregations without relying on SQL (via DuckDB), Polars is the way to go.
Multi-Engine Support
This goal is the most challenging one. To run multiple query engines on the data in the same S3 bucket, we need a coordinating service that can process metadata changes. These coordinators are called "technical catalogs" (or just "catalogs") in Iceberg. If you don't have a coordinator, multiple engines work directly on files in storage. When writing to a table concurrently, they could overwrite the most recent metadata version, messing up your lakehouse.
The requirement for a metadata change coordinator is why you should refrain from using the older Hadoop Iceberg catalog in production environments where concurrent writes are possible. We also caution against using Polars' "feature" to access Iceberg tables directly, circumventing a catalog unless you are doing this in development, only to read data, or are the only user of the lakehouse.
This leads us to the next big question.
Which Iceberg catalog should you use for an open, multi-engine data lakehouse?
Our answer might be surprising—we chose Snowflake's Open Catalog, a managed service separate from Snowflake's main data warehousing product. You might wonder why we went with a product from a company that is potentially threatened by the emerging open darta lakehouses. In a couple of days, we will publish a post that explains why Open Catalog came up on top in our evaluation and will also walk you through the catalog's setup.
But that's for later. Today, we will review how Iceberg stores table data and metadata. This little data exploration will show you how critical it is not to mess around with the table metadata file. Every change operation on data or schema (Inserts, Deletes, Updates, or adding/modifying columns) of a table will result in a new metadata file, and we need a catalog service to coordinate all of that.
Next Steps
Here is what we plan to do next:
-
Set up a local environment for exploring Iceberg storage and understand how Iceberg stores table data and metadata (read our post now!)
-
Review why Snowflake's Open Catalog ended up being a top choice for managed Iceberg catalogs (at least for the time being) (follow us on Linkedin or sign up for our Substack newsletter to get notified when we publish this post)
-
Tie everything together and show how one can use only Python tools (PyArrow and Polars) to run data applications on top of an S3-based open data lakehouse.
See you in Iceberg Land after the jump.