

Serhii Sokolenko
The 10x data team at Taktile, enabled by Tower and dltHub

How everyone at Taktile can build production-ready data pipelines with Tower and dltHub’s dlt and dlt+
Last week our design partner Taktile shared how they made it incredibly easy for everyone across the organization to contribute to the creation of high-quality data sets, thanks to dltHub and Tower. Taktile went from a team of 2 data engineers capable of making changes to their data platform to pretty much everyone who knows a bit of Python. Taktile used dltHub for data extraction, loading and transformation, and Tower to simplify team collaboration and create environments with shared secrets and dependencies. Tower also served as a portable Python runtime that enabled smooth transition from local development to cloud testing and production.
Simon Rosenberger, the Head of Data Platform at Taktile, said it best: “Tower is like Docker, Dagster, and Jenkins having a baby 🐳+ 🐙+ 🤵🏼♂️ = 💜”.
Simon - we love your emojis and your analogy! Both Tower founders started their careers by making small contributions to children's health (read our inaugural blog). To understand why Simon was so excited about Tower, it’s worth listening to his talk, one of the highlights of the dltHub Portable Data Lake event.
Taktile is the leading decision intelligence platform for FinTechs around the world. Taktile’s data team operates a Snowflake data warehouse and onboards data from a large number of data sources including clickstreams, server logs, cloud cost reports, CRM data, internal knowledge bases, customer support tickets etc. To onboard an ever increasing number of data sources they chose to implement new pipelines using the dlt library from dltHub. Dlt provides a wide range of supported sources and sinks, schema detection, incremental and full loads and many other features. A unique feature of dlt is that it’s an in-process Python library that can be embedded into any Python data application. Taktile has already built 10+ of these dlt-based pipelines, orchestrated by and executed on Github Actions.
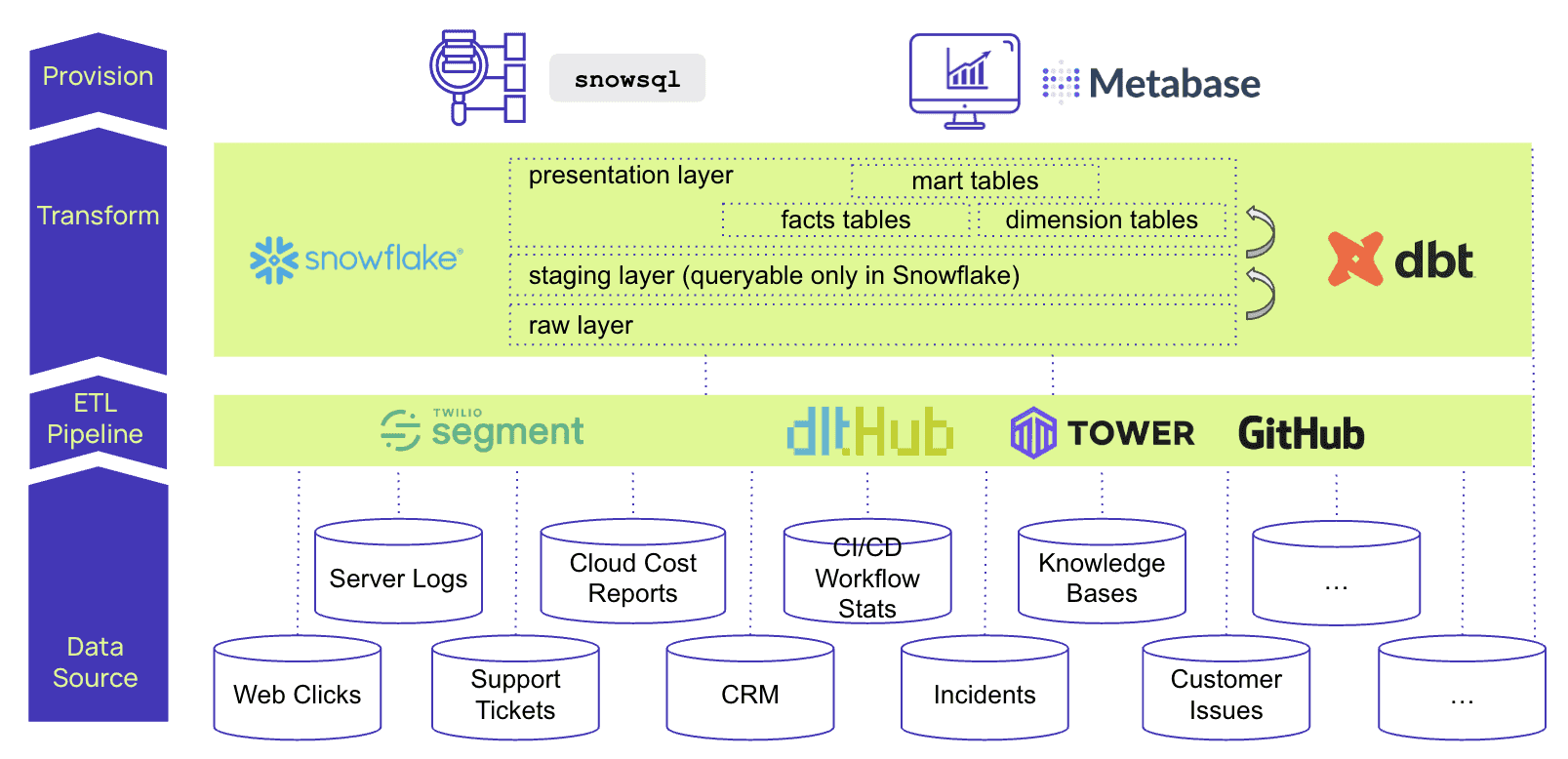
The entire data platform was built by a very lean data team - it’s just Simon and a colleague of his. This team constantly gets requests to make changes and onboard new data, so they decided to broaden the group of people who can make changes to data pipelines to literally everyone at Taktile who knows a bit of Python, becoming 10x more productive as a result. To get there, they needed help with maintaining consistent development environments on all their employee’s laptops, and in production.
This is where Tower came in. Secrets necessary for accessing data sources can be securely shared between team members in Tower. Teams can define Tower environments that contain secrets and other configuration settings, and these secrets and configs can be the same or different, allowing one for example, to write into a local file system in a dev environment and to a Snowflake instance in production.
Tower also integrates deeply with the new dltHub offering dlt+. Tower secrets are seamlessly mapped to dlt secrets at runtime, Tower environments are mapped to dlt+ profiles etc. Tower is an early supporter of dlt+ and worked with dltHub on creating a reliable production runner for dlt+ projects.
Simon’s team implemented a new pipeline pumping project issues data from Linear to their data warehouse using dlt and Tower. In this demo Simon shows how easy it is now for his non-engineering colleagues to extend the pipeline and e.g add new fields to the data flow.
If you are a data platform team that is concerned about the productivity of your engineers, or are looking for a reliable way to run Python data applications in production, please reach out to us, the Tower Founders, via this link. We would be happy to chat with you about your use case and enable you for our private beta.
Update March 2025: Improved support for Teams has been added to Tower. Check out our announcement.