We’re excited to announce support for data engineering AI Agents in Tower! You can now deploy agents that orchestrate data processing tasks based on your goals and the tools you provide.
This builds on Tower’s orchestration framework launched last month. In addition to scripting control flows using run and wait, you can now let agents reason what actions need to be performed. Any Tower app can serve as a tool in these agentic workflows.
Agents won’t replace data engineers, but they’re useful as first-pass flow designers (with human oversight) or for automating tedious tasks.
We recently shared our vision for AI Agents working with enterprise data. We reflected on past chatbot failures—like the lawyer who cited fake cases and got fined—and argued that giving agents access to live operational and analytical stores can prevent such issues. As analytics shifts to open formats like Apache Iceberg, agents must learn to “speak Iceberg.”
In this post, we’ll explore how AI Agents operate in Tower and how they’re empowered to work with Iceberg-based data.
How Do AI Agents Actually Work?
AI Agents act as orchestrators. They operate in a reasoning loop, using frameworks like LangChain to decide which actions—called “tools”—to execute based on the user’s input. These tools feed information into large language models (LLMs) such as GPT-4o, Claude 3, or OpenAI’s Assistant API.
If you’ve used ChatGPT and seen messages like “Searching the web” or “Using code interpreter,” you’ve seen this in action. That’s exactly how AI Agents work: by delegating tasks to tools and interpreting the results.
LangChain agents, for example, follow a structured reasoning-action loop:
Receive user input (e.g., “Update stock ticker data in my data warehouse”).
Send the input to the LLM, along with descriptions of available tools.
The LLM selects a tool to use and invokes it.
Tool output is returned as an observation to the LLM.
The loop continues, with the LLM deciding on the next action based on the latest observation.

After this final stage, agents can optionally store the interaction (both the prompt and the output) in what’s called “memory.” This enables them to refer back to previous conversations, allowing for more context-aware and personalized interactions in the future.
It’s All in the Name (and the Description)!
The effectiveness of agentic orchestration hinges on how well you define the agent’s goal and its environment. This means selecting the right prompt template and clearly describing, in plain English, both the task and the tools the agent can use.
To set up an agent, you’ll need to define or select the following components:
Prompt template — e.g., “ReAct”, “Structured Chat”, or “OpenAI Tools”
Tool names and descriptions — short text explaining what each tool does
User input — the high-level goal or task you want the agent to perform
Initial action input — parameters or starting data for the task
By the way, the name ReAct comes from Reasoning + Action. The ReAct prompt template guides the agent to alternate between reasoning steps and actions it takes using tools.
Here’s an example of a ReAct prompt template, originally shared by Harrison Chase, the founder of LangChain:
Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}Notice the placeholders like {tools}, {tool_names}, {input}, and {agent_scratchpad} in the prompt template? These will be dynamically filled in with actual values that you define in your code.
For example, here’s a tool definition that checks whether stock data exists in a table. In this definition, we specify what the tool does, its input parameters, and what it returns. The language model uses these descriptions to decide whether to invoke the tool and how to interpret its output.
This tool definition will be inserted into the {tools} and {tool_names} sections of the prompt.
check_ticker_data_available_tool = Tool(
name="check_ticker_data_available",
func=check_ticker_data_available,
description="""Checks if the data for given ticker and pull date is already available.
Input must be a JSON string with PULL_DATE and TICKER keys.
Example input: {"PULL_DATE": "2025-05-25", "TICKER": "AAPL"}.
If the data is available, tool returns a message saying so.
"""
)check_ticker_data_available_tool = Tool(
name="check_ticker_data_available",
func=check_ticker_data_available,
description="""Checks if the data for given ticker and pull date is already available.
Input must be a JSON string with PULL_DATE and TICKER keys.
Example input: {"PULL_DATE": "2025-05-25", "TICKER": "AAPL"}.
If the data is available, tool returns a message saying so.
"""
)check_ticker_data_available_tool = Tool(
name="check_ticker_data_available",
func=check_ticker_data_available,
description="""Checks if the data for given ticker and pull date is already available.
Input must be a JSON string with PULL_DATE and TICKER keys.
Example input: {"PULL_DATE": "2025-05-25", "TICKER": "AAPL"}.
If the data is available, tool returns a message saying so.
"""
)The next key input for the agent is the user input—the actual task or goal you want the agent to perform. For example, if your goal is to update stock ticker data in a data warehouse, the user input might look like this:
user_input = """
Get the ticker data for the given pull date and the given list of tickers.
Get the ticker data one by one.
Before getting the data for each ticker, check if it is already available.
"""
user_input = """
Get the ticker data for the given pull date and the given list of tickers.
Get the ticker data one by one.
Before getting the data for each ticker, check if it is already available.
"""
user_input = """
Get the ticker data for the given pull date and the given list of tickers.
Get the ticker data one by one.
Before getting the data for each ticker, check if it is already available.
"""
It’s also possible to add parameters to user input, right after “Action Input”.
input_params = {"PULL_DATE": pull_date, "TICKERS": tickers}
full_input = f"{user_input}\n\nAction Input: {json.dumps(input_params)}"input_params = {"PULL_DATE": pull_date, "TICKERS": tickers}
full_input = f"{user_input}\n\nAction Input: {json.dumps(input_params)}"input_params = {"PULL_DATE": pull_date, "TICKERS": tickers}
full_input = f"{user_input}\n\nAction Input: {json.dumps(input_params)}"Once you've defined your prompt, tools, LLM, and user input, you're ready to create the agent and invoke it with the user input.
agent = create_react_agent(llm=llm, tools=tools, prompt=prompt)
executor = AgentExecutor(agent=agent, tools=tools, verbose=True, handle_parsing_errors=True)
response = executor.invoke({"input": full_input})
agent = create_react_agent(llm=llm, tools=tools, prompt=prompt)
executor = AgentExecutor(agent=agent, tools=tools, verbose=True, handle_parsing_errors=True)
response = executor.invoke({"input": full_input})
agent = create_react_agent(llm=llm, tools=tools, prompt=prompt)
executor = AgentExecutor(agent=agent, tools=tools, verbose=True, handle_parsing_errors=True)
response = executor.invoke({"input": full_input})
Where Does Iceberg Fit In?
In one of our recent posts, we explained that Agents can’t rely solely on LLMs—they need access to live analytical and operational data to provide accurate answers. The standard way to enable this is by giving agents tools—literally.
Earlier, we looked at the definition of a tool called check_ticker_data_available_tool. But what does this tool actually do? In the tool declaration, we provided a brief description and specified the name of the underlying function: check_ticker_data_available.
check_ticker_data_available_tool = Tool(
name="check_ticker_data_available",
func=check_ticker_data_available,
description="""..."""
)
check_ticker_data_available_tool = Tool(
name="check_ticker_data_available",
func=check_ticker_data_available,
description="""..."""
)
check_ticker_data_available_tool = Tool(
name="check_ticker_data_available",
func=check_ticker_data_available,
description="""..."""
)
Here’s what the function looks like. It uses Tower’s simple Iceberg tables API to query the table and check for data availability. Tower handles Iceberg catalog integration behind the scenes, so developers can reference the table by name—like "daily_ticker_data"—without extra setup.
Bonus points if you noticed that the function accepts parameters. The agent knows which parameters to pass by reading the tool’s description text—no extra wiring needed.
def check_ticker_data_available(input_str: str) -> str:
params = json.loads(input_str)
table = tower.tables("daily_ticker_data").load()
df = table.to_polars()
matching_rows = df.filter(
(pl.col("ticker") == params["TICKER"]) &
(pl.col("date") == params["PULL_DATE"])
).collect()
if matching_rows.height > 0:
return f"Data already exists for ticker {params['TICKER']} on date {params['PULL_DATE']}\n\n"
else:
return f"No data found for ticker {params['TICKER']} on date {params['PULL_DATE']}\n\n"
def check_ticker_data_available(input_str: str) -> str:
params = json.loads(input_str)
table = tower.tables("daily_ticker_data").load()
df = table.to_polars()
matching_rows = df.filter(
(pl.col("ticker") == params["TICKER"]) &
(pl.col("date") == params["PULL_DATE"])
).collect()
if matching_rows.height > 0:
return f"Data already exists for ticker {params['TICKER']} on date {params['PULL_DATE']}\n\n"
else:
return f"No data found for ticker {params['TICKER']} on date {params['PULL_DATE']}\n\n"
def check_ticker_data_available(input_str: str) -> str:
params = json.loads(input_str)
table = tower.tables("daily_ticker_data").load()
df = table.to_polars()
matching_rows = df.filter(
(pl.col("ticker") == params["TICKER"]) &
(pl.col("date") == params["PULL_DATE"])
).collect()
if matching_rows.height > 0:
return f"Data already exists for ticker {params['TICKER']} on date {params['PULL_DATE']}\n\n"
else:
return f"No data found for ticker {params['TICKER']} on date {params['PULL_DATE']}\n\n"
How to Deploy Orchestrating Agents in Tower
Deploying agents in Tower is straightforward. We recommend creating a Tower app that instantiates a LangChain agent and defines the tools it will use. These tools can even call other Tower apps!
Our vision is to make any Tower app usable as an agentic tool by any other app—enabling composable, agent-driven workflows.
For example, if you want to define a tool that invokes another Tower app, simply create a function and declare a corresponding Tool that points to it:
def get_data_for_ticker(input_str: str) -> str:
params = json.loads(input_str)
app_params = {
"PULL_DATE": f"{params['PULL_DATE']}",
"TICKERS": f"{params['TICKER']}"
}
print(f"Calling data write app with parameters: {app_params}")
run = tower.run_app("write-ticker-data-to-iceberg", parameters=app_params)
run = tower.wait_for_run(run)
if run.status_group == "successful":
return f"Data for ticker {params['TICKER']} on date {params['PULL_DATE']} has been downloaded and upserted into the table.\n\n"
else:
return f"Data for ticker {params['TICKER']} on date {params['PULL_DATE']} has not been downloaded and upserted into the table.\n\n"
def get_data_for_ticker(input_str: str) -> str:
params = json.loads(input_str)
app_params = {
"PULL_DATE": f"{params['PULL_DATE']}",
"TICKERS": f"{params['TICKER']}"
}
print(f"Calling data write app with parameters: {app_params}")
run = tower.run_app("write-ticker-data-to-iceberg", parameters=app_params)
run = tower.wait_for_run(run)
if run.status_group == "successful":
return f"Data for ticker {params['TICKER']} on date {params['PULL_DATE']} has been downloaded and upserted into the table.\n\n"
else:
return f"Data for ticker {params['TICKER']} on date {params['PULL_DATE']} has not been downloaded and upserted into the table.\n\n"
def get_data_for_ticker(input_str: str) -> str:
params = json.loads(input_str)
app_params = {
"PULL_DATE": f"{params['PULL_DATE']}",
"TICKERS": f"{params['TICKER']}"
}
print(f"Calling data write app with parameters: {app_params}")
run = tower.run_app("write-ticker-data-to-iceberg", parameters=app_params)
run = tower.wait_for_run(run)
if run.status_group == "successful":
return f"Data for ticker {params['TICKER']} on date {params['PULL_DATE']} has been downloaded and upserted into the table.\n\n"
else:
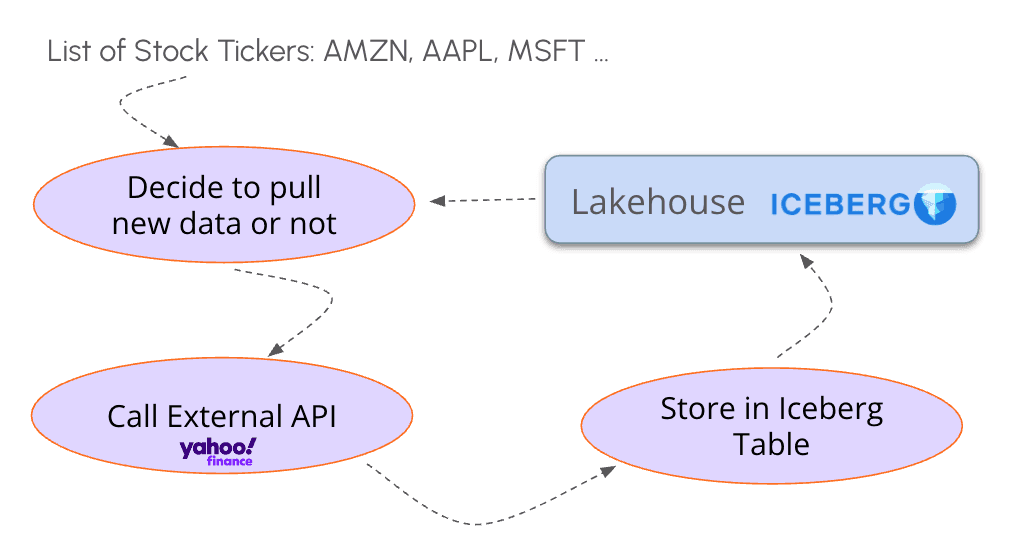
return f"Data for ticker {params['TICKER']} on date {params['PULL_DATE']} has not been downloaded and upserted into the table.\n\n"To demonstrate how this works in Tower, we’ve created a sample app called ticker-update-agent, available on GitHub. This example defines an agent responsible for maintaining an Iceberg table with stock ticker data—specifically open, close, and volume for each date.
The agent is equipped with tools to check whether data already exists in the table and to fetch missing data from an external API. When you run the example, you’ll see how the agent reasons through which tickers need updating and which can be skipped—avoiding redundant API calls while keeping your Lakehouse data fresh and up to date.
Next Steps
To evaluate agentic orchestration on Tower:
Sign up for Tower
Clone the Ticker Update Agent example from GitHub
→ Get the Ticker Update Agent example
Run the example and observe agentic orchestration in action!

