
Serhii Sokolenko
Preparing Your AI Agents for the Iceberg Age

Imagine trusting an AI chatbot for legal research, only to be fined $5,000 and having your case dismissed because it fabricated case law. That’s exactly what happened in 2023 to a New York lawyer who misunderstood the difference between generative AI and reliable data retrieval.
The lawyer was working on a case for a plaintiff who sued an airline, claiming an injury during a flight. The law firm used ChatGPT to research the case and identify precedents. ChatGPT claimed to find similar cases and the lawyer submitted the brief without verifying the authenticity of the citations.
It’s a cautionary tale that underscores the central challenge of today’s AI tools: knowledge without factual grounding is a liability.
In a world increasingly powered by language models, we must go beyond generic chatbots. We need agents that can think, act, and—most critically—retrieve the right data.
From Chatbots to Agents with Tools
Legacy chatbots were simple. They took your prompt, added some context using RAG or CAG techniques, and let the LLM (like GPT or Llama) generate the response based on what was statistically the most probable sequence of words judging by its training corpus. But that’s no longer enough.
Modern agents build on LLMs, but instead of generating the response in one shot, they use a reasoning technique to create a workflow - if this is true then do that, and if that happens, then do the next thing. In this workflow they use so-called “tools” that access APIs and analytical and operational databases. This allows them to stay grounded in truth. This is a radical shift.
How did we get there? Let’s take a look.
LLMs are a new form of databases
Before LLMs, we relied on data warehouses, operational dashboards, and Google to find the answers we needed. Today, LLMs are emerging as a new kind of database. As Tim Scarfe, host of ML Street Talk, puts it:
“LLMs perform diffused retrieval given a prompt—they’re essentially databases, a new form of database.”
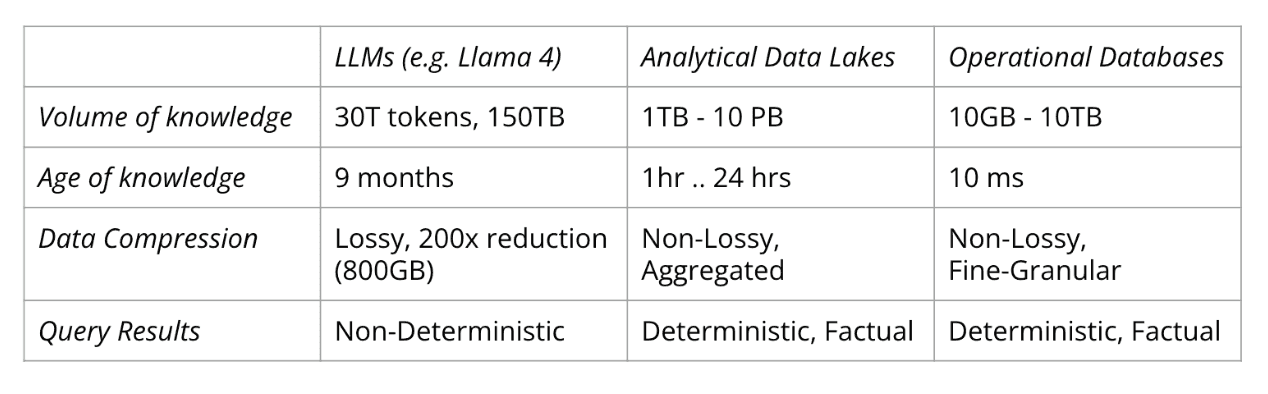
That analogy holds up. Prompts resemble queries, and LLM responses mirror database result sets. What’s unique about LLMs is how they compress knowledge. For example, Llama 4 was trained on 30 trillion tokens—roughly 150 TB of text—but ends up as an 800 GB model. That’s a 200x compression, with inevitable information loss.
And that’s acceptable. We trade some precision for a system that can reason and generate novel responses—something that feels almost human. That’s the magic of LLMs.
Still, while we’re comfortable getting life and professional advice from something that fits on the hard drive of a laptop, we don’t want to repeat the mistakes made by overconfident lawyers. The solution? Combine the generalized knowledge of LLMs with real-time data from analytical and operational databases.
Complementing LLM Knowledge with Live Data from Data Stores
Analytical databases—like Snowflake or Oracle—power dashboards and data analysts. Today, they’re often called data lakes or lakehouses. Operational databases, such as PostgreSQL or MySQL, support transactional systems like CRMs, POS systems, and web apps, storing data on sales, customers, inventory, and more.
LLMs, analytical stores, and operational databases serve different but complementary roles. LLMs excel at producing responses that feel intelligent across a wide range of prompts. But they have limits: their knowledge is months old due to slow training cycles, and their training data (e.g., 150 TB for Llama 4) pales in comparison to the petabytes enterprises store in data lakes. More critically, LLMs lack access to recent transactions—information that lives in operational databases.
Bringing these systems together bridges the gap between reasoning and real-time data.
Will LLMs Merge with Other Data Stores?
Wouldn’t it be convenient if LLMs could be stored alongside analytical and operational databases—since they’re all just databases at heart?
While appealing in theory, it’s unlikely in practice—at least for the next 5–10 years. These systems serve different purposes and rely on very different technologies. LLMs must be served from memory at inference time, unlike traditional databases.
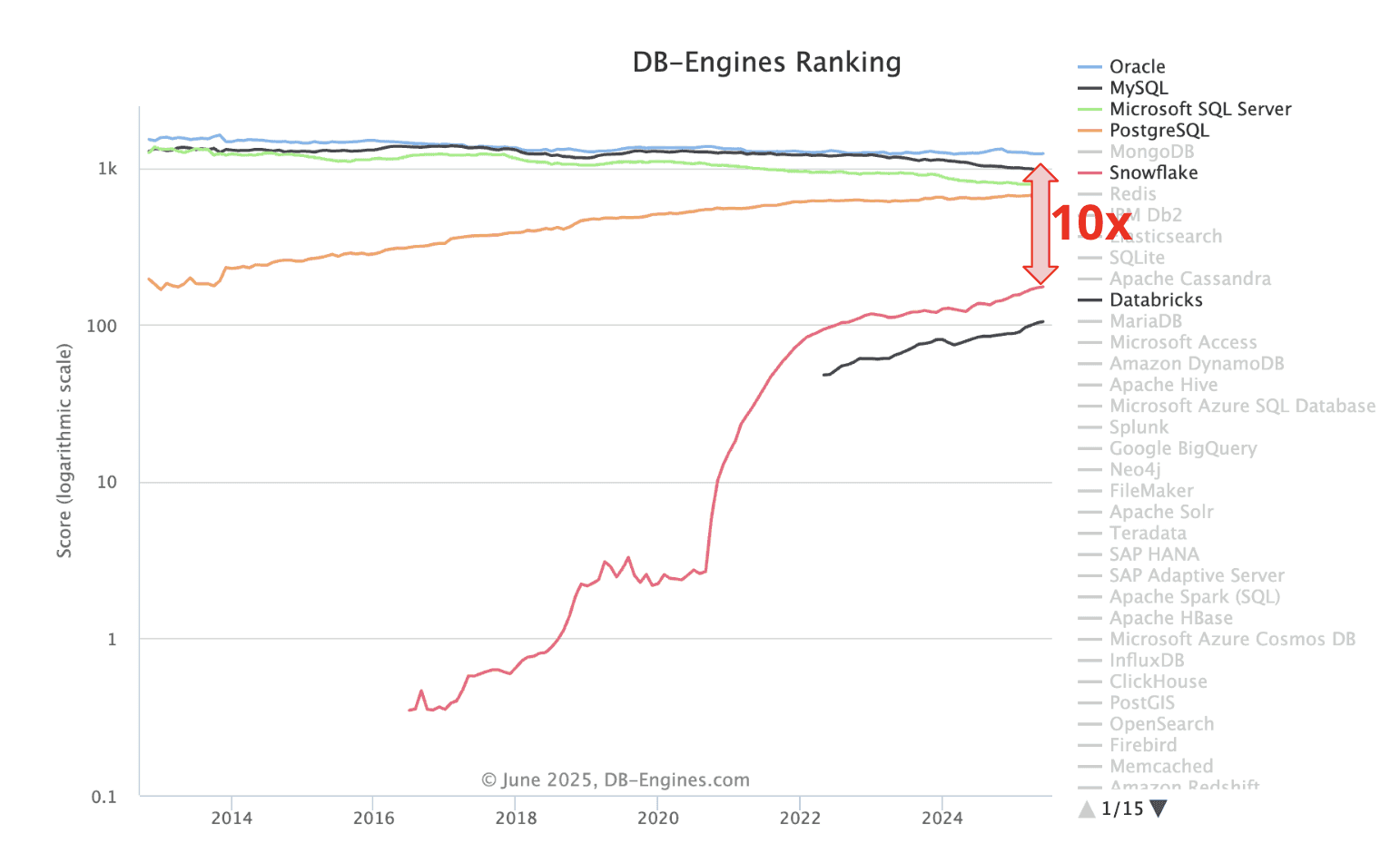
History also shows how slow change comes to the database world. The top three databases—Oracle, MySQL, and SQL Server—have dominated the DB-Engines Ranking for over a decade. Even PostgreSQL, a rising star recently tied to acquisitions by Databricks (Neon) and Snowflake (Crunchy Data), has taken 10 years to approach the top—but hasn’t cracked it yet.
Databricks and Snowflake themselves are growing rapidly, with popularity scores nearing 100. But Oracle still stands at over 1000! Replacing core database tech is slow because it means rewriting the countless applications that depend on it.
Analytical and operational databases aren’t going anywhere—so we need to teach LLMs how to work with them. Over the past few years, the industry has explored several approaches: Retrieval-Augmented Generation, Context-Augmented Generation, and now, Agentic Orchestration.
We’ll dive into the agentic approach shortly. But first, let’s look at a key trend currently reshaping the analytics landscape.
Apache Iceberg: The Future of Analytical Storage
The world of analytical data storage is shifting toward open standards. Previously, companies would pick a service—Snowflake for warehousing, Databricks for ML and data engineering, or Fabric for Microsoft ecosystems. Though these platforms often ran on the same clouds (AWS, Azure, Google Cloud) and used similar file formats (like Parquet or ORC), they differed in how data was organized into usable tables.
To share data across platforms, companies relied on costly ETL processes, duplicating storage and wasting compute. Industry estimates suggest up to 40% of analytical compute was spent just on ETL.
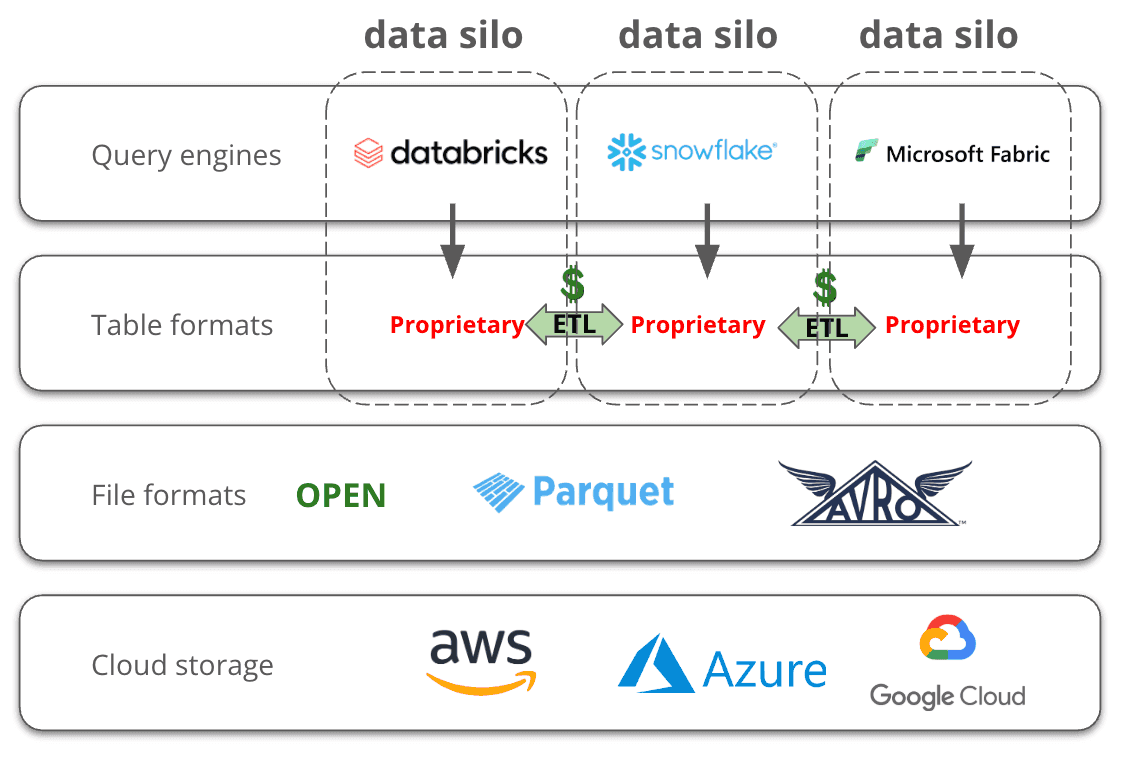
In the mid-2010s, major cloud users like Netflix and Apple pushed back. Frustrated with data lock-in (e.g., in Redshift), they demanded open formats and used contract negotiations to pressure providers into supporting them. I was at AWS at the time and saw Netflix driving this push firsthand.
In 2019, Netflix open-sourced what became Apache Iceberg—a table format now seeing hockey-stick growth.
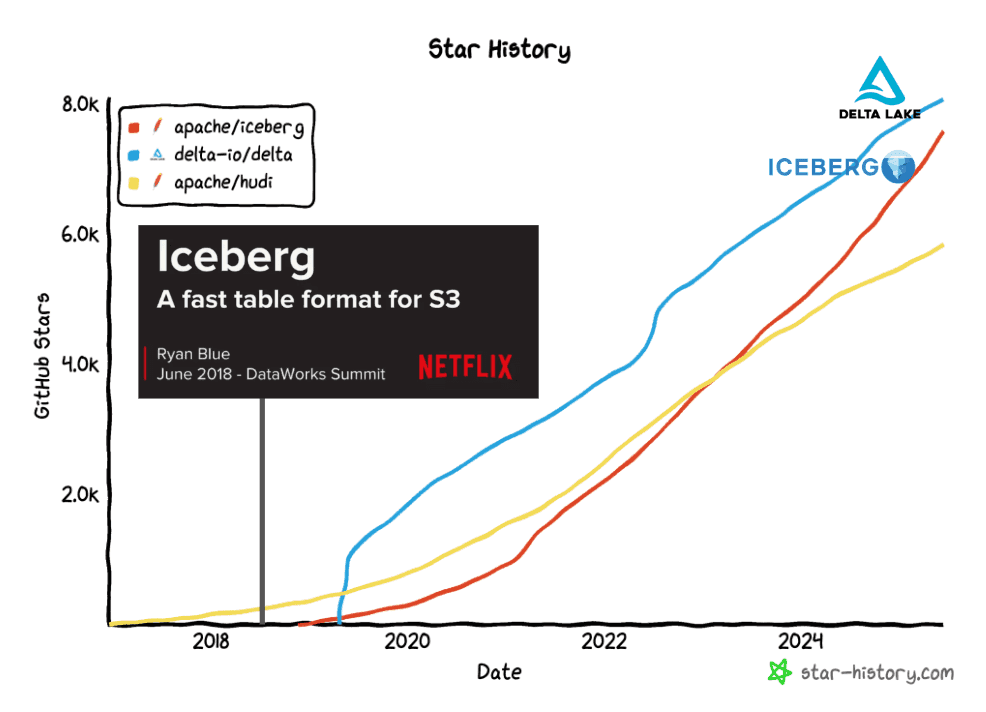
Iceberg lets companies truly own their data, store it in S3 or on-premises, and use different compute engines like Snowflake or Databricks without copying data around. Instead of duplicating datasets across silos, all engines can work off the same source of truth. As a result of this trend, AI agents of the future will need to “speak Iceberg” to access the vast volumes of enterprise analytical data.
What’s expected from Analytical Tools for Agents?
The two key considerations for analytical tools used by agents are:
1. Query Throughput
AI agents will run far more analytical queries than human analysts—often 100 times more.
Adrian Brudaru, co-founder of dltHub, offers an example. If you notice a spike in sales at a specific time and ask an agent to investigate, the agent will issue numerous exploratory queries—checking for anomalies, slicing data by segments and dimensions.
Unlike humans, agents lack contextual memory. A human might know when to stop digging; an agent doesn't. Humans also face friction when seeking help from other teams—they need to justify their request. Agents, however, "have no scruples" and will fire off as many queries as needed without hesitation.
This means significantly higher query volume, which makes Iceberg’s performance and scalability especially valuable.
2. Data Security
To ensure agents handle data responsibly, a data authorization safeguard is necessary. Depending on its task, the agent should only access the data the human user is permitted to see, or only the data that the agent needs to accomplish the task. In the database world, the Data Catalog is a critical piece that enforces access rules and permissions. It is common to employ the following techniques:
Column Masking: Hiding sensitive PII data unless explicitly authorized.
Row-Level Filtering: Restricting access to only the relevant subset of data.
How is Apache Iceberg Delivering on these Expectations?
1. Query Throughput
Iceberg’s Read performance is excellent, thanks to a scalable architecture that builds on cloud-native storage like S3 and Azure Blob storage.
Write performance is still a work in progress, but the Iceberg community is actively improving it.
2. Data Security
This area is still work-in-progress, as only a few Iceberg catalogs currently support advanced security features like row filters and column masking.
Notable solutions include Lakekeeper by Vakamo and Unity Catalog from Databricks
Viktor Kessler, CEO of Vakamo and one of the creators of the Lakekeeper catalog, says:
"When building an AI agent, you often don’t know where the data resides, how reliable it is, or whether its use complies with internal policies or external regulations. Some data may contain personally identifiable information (PII) or confidential corporate insights—if accessed by the wrong party, it can pose serious legal and compliance risks.
The right answer often depends on who is asking—an analyst, a CEO, a customer, or an AI-powered application. Retrieval-Augmented Generation (RAG) systems, for example, may require different levels of context, access, or redaction to deliver accurate and compliant results. Lakekeeper is built to support this kind of contextual governance, serving as a unified data & AI governance control plane purpose-built for AI and analytics workloads."
Viktor also points to growing support for emerging standards like OpenFGA and RBAC in the Iceberg community.
Agentic Platforms with easy Iceberg access
Today, several platforms make it easy for customers to deploy agents with seamless access to Iceberg data. One example is Tower.dev, a serverless Python platform designed for data teams who want to build pipelines, apps, and agents—without managing complex infrastructure.
At the heart of Tower are modular building blocks: Tables, Models, and Apps. These are supported by a layer of horizontal services—called “beams”—which provide orchestration, observability, and team collaboration capabilities.
A core concept in Tower is the App. Some Tower apps function as agents that orchestrate end-to-end workflows. Others serve as tools used by agents to access operational or analytical data, or to interact with external APIs. Still others are traditional ETL pipelines.
Tower also integrates with popular open-source libraries to offer built-in support for database tools. For operational data, it provides integrations with DuckDB and dltHub. For analytical workloads, it offers easy, native access to Iceberg tables.
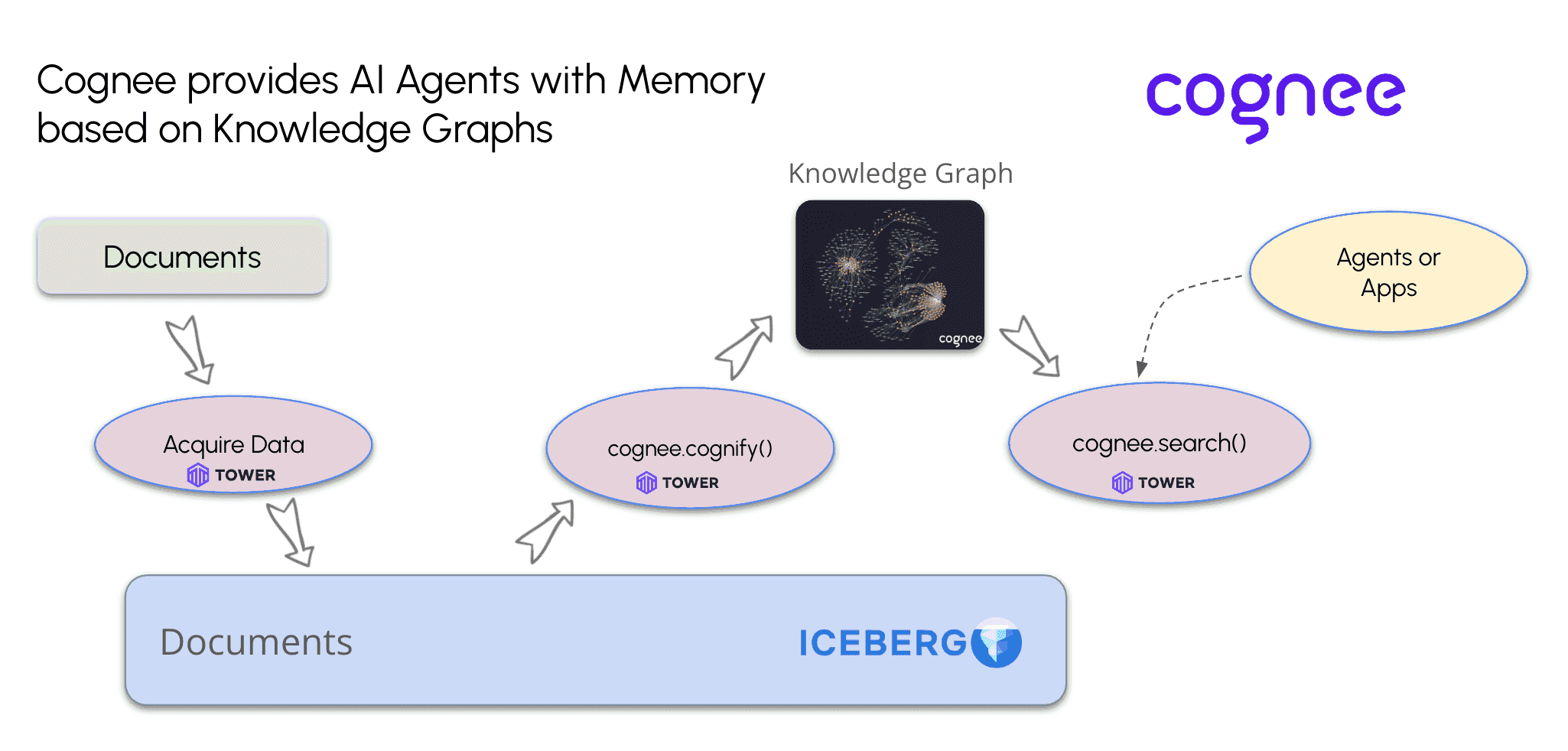
One of Tower’s users, Cognee, specializes in AI memory systems powered by knowledge graphs and vector stores. Cognee uses Tower to ingest data from external APIs and store it as documents in Iceberg tables. Tower also supports search functionality when external apps or agents query the knowledge graph. In those cases, the “cognify” process is triggered, transforming Iceberg documents into a searchable knowledge graph for Cognee users.
Takeaways & Next Steps
Here are three key takeaways with the most important insights:
Augmenting the Knowledge Gap: Avoid the pitfalls of outdated LLMs by augmenting them with access to fresh, real-time data.
Iceberg is the Analytical Future: Apache Iceberg is emerging as the foundational format for tomorrow’s analytical data stores.
Think Business Value: Use agentic frameworks like LangChain and agent-compatible platforms like Tower to get to business value faster.
Want to learn more?
Tower announces support for deploying and operating AI agents