
Simon Rosenberger
Tower tried dltHub Pro and here’s why we think you should too!

At Tower, we build infrastructure for teams who run modern data products at scale. We partner with platform builders like dltHub- who are creating the open, Pythonic data ingestion and transformation layer- to deliver turnkey solutions. We run the machines, they build the services.
We’ve been privileged to be early test users of dltHub Pro, their new agentic data platform. Here’s what we think:
How fast does dltHub Pro take my pipeline to production?
In minutes, really!
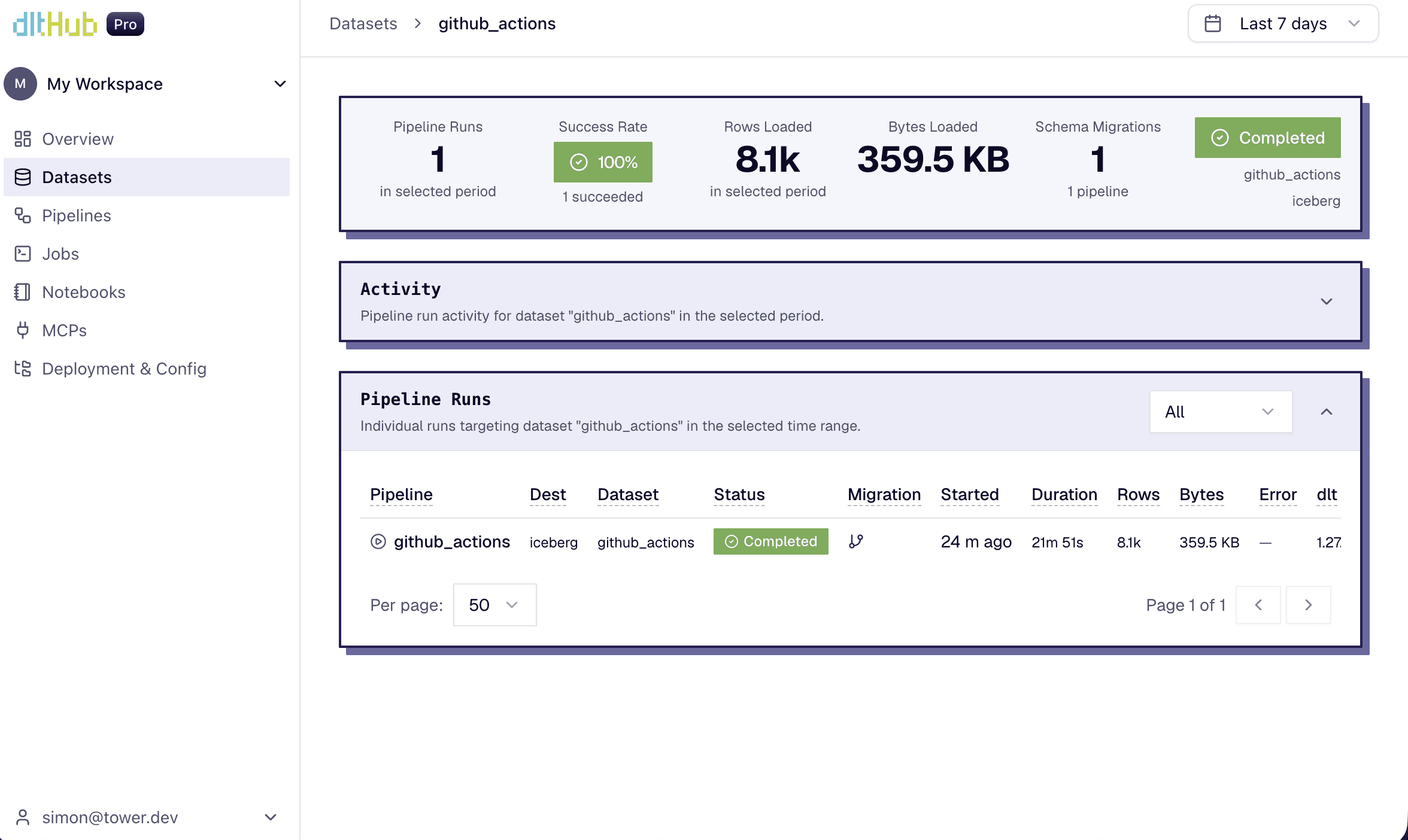
I asked an agent to build a pipeline that loads GitHub Actions workflow runs into Tower's Iceberg Lakehouse. Three minutes later, I had working code. Five minutes after that, it was deployed and running in production.
No boilerplate. No framework migration. No “Day 2” surprise when you realize the docs lied about pagination. The agent handled auth configuration, schema inference, nested JSON flattening, and Polaris catalog setup, all from a few simple prompts.
If you’re a data professional, you’re in the business of delivering metrics and insights. Not debugging YAML indentation at 11pm.
Does dltHub Pro have agents?
Actually, it’s built to be agent-first.
I comes with well-thought-out abstractions, a few Python decorators, a slim CLI, and ready-made agent skills that organize the tedious work for you. Pagination logic, retry handling, credential wiring, schema mapping: Claude writes it, you review it.
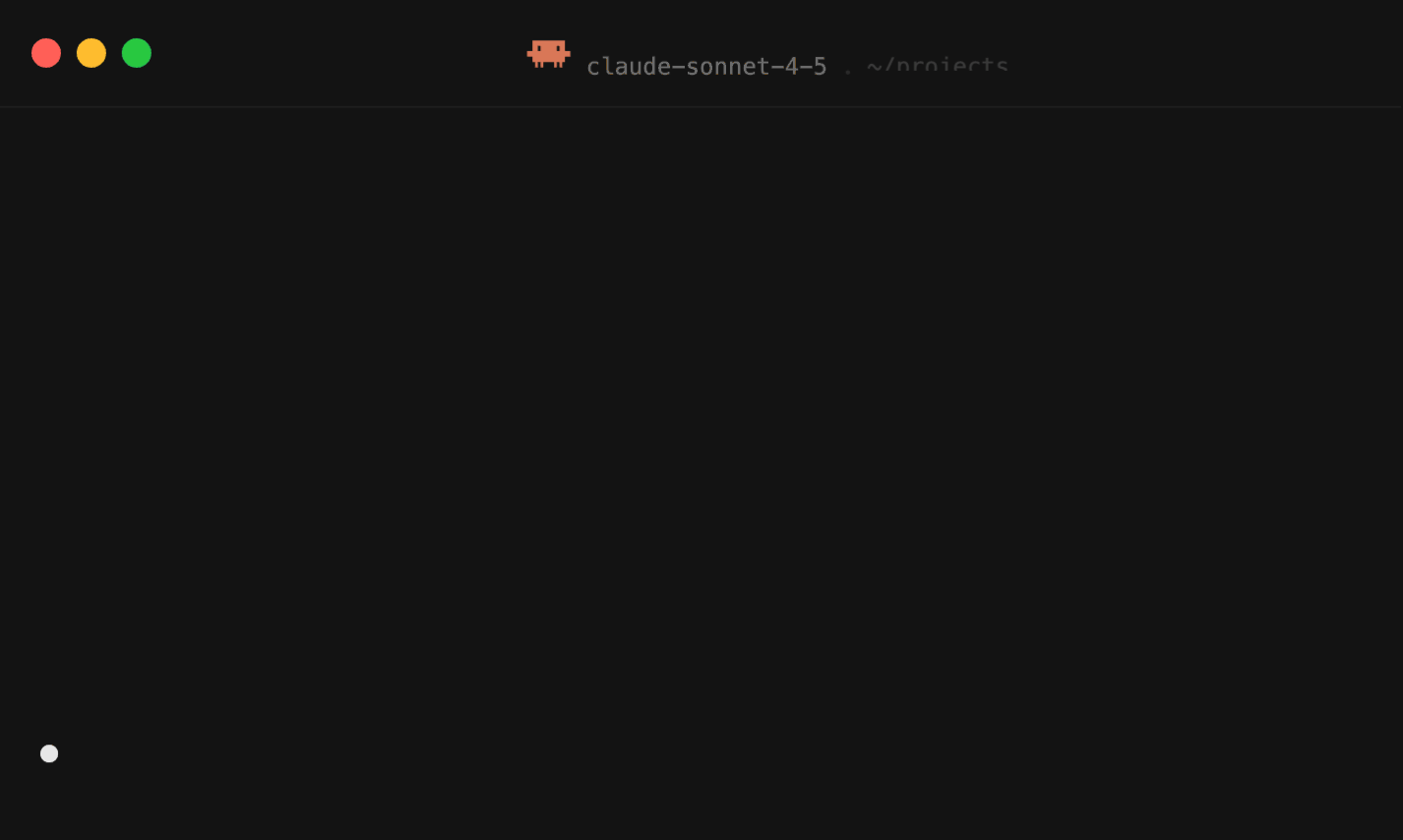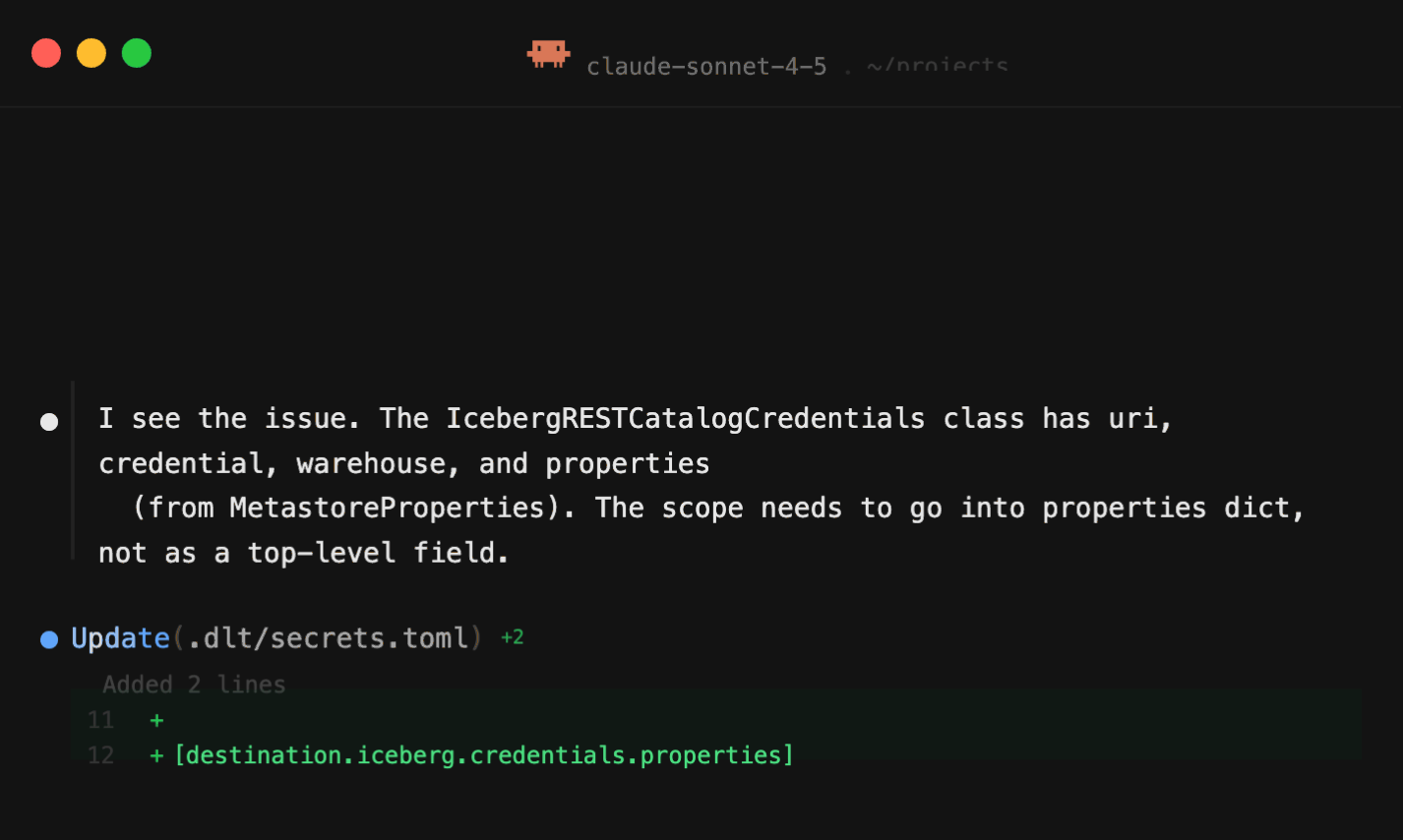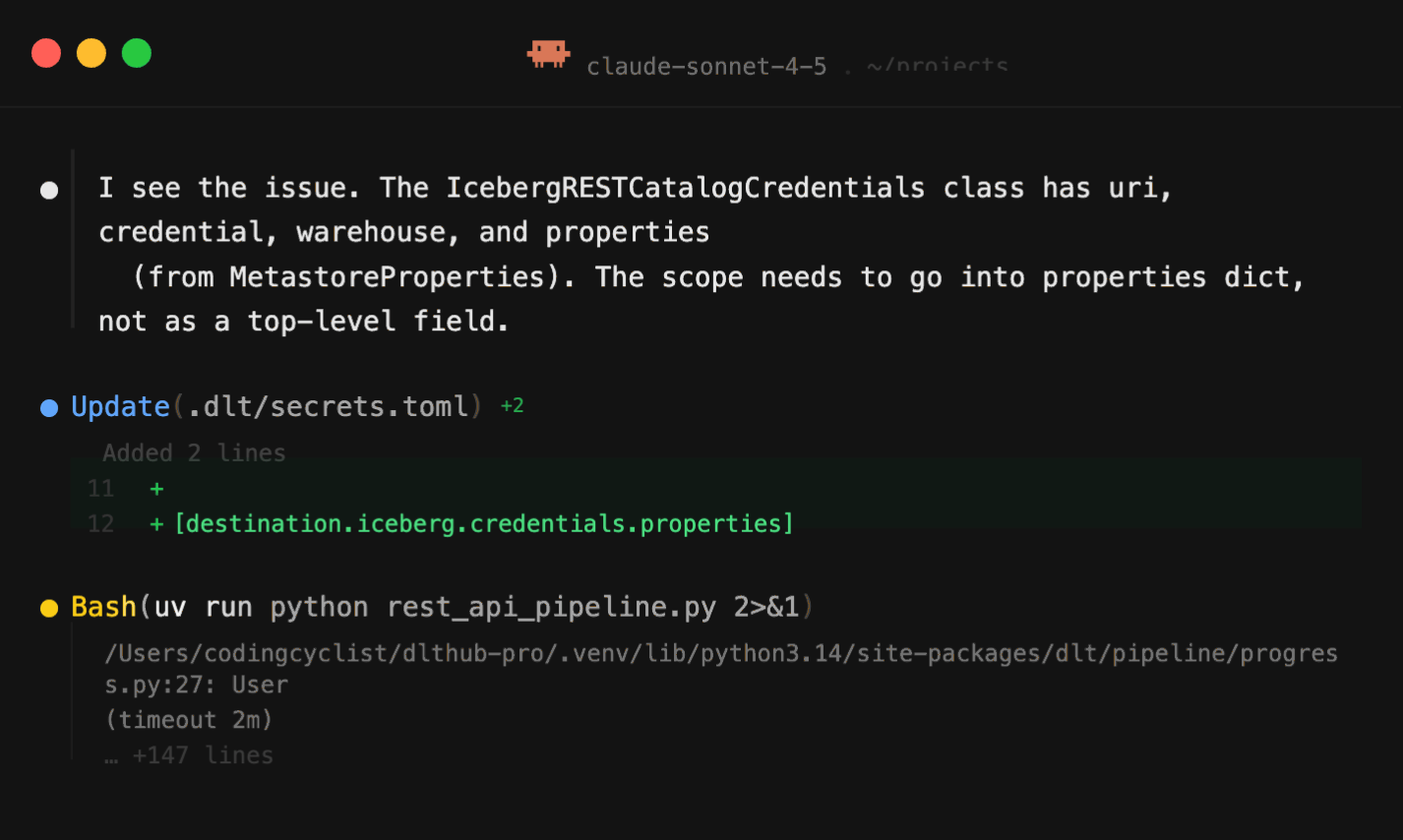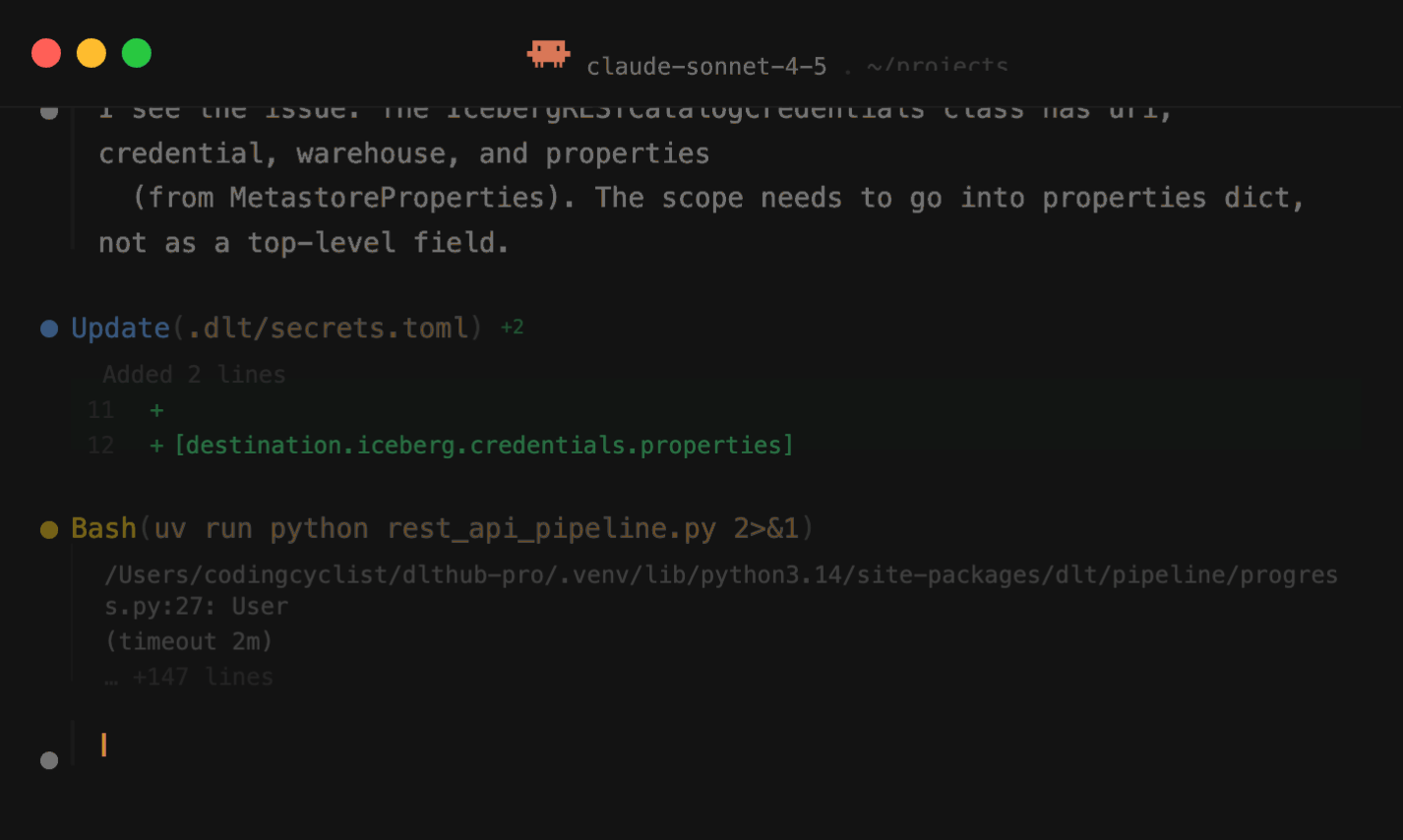
The abstraction level is exactly right. Durable enough for production. Light enough that you can read every line. When I needed to trim my workflow runs table from 150 columns to 15, the agent did it in one shot. When the Polaris OAuth scope was wrong, it diagnosed the error and told me exactly what to fix.
Can I save money using dltHub Pro?
Absolutely!
The typical data stack from source to insight requires at least four vendors: ingestion, storage, transformation, quality, visualization. Each with its own auth, its own CLI, its own billing page, its own breaking changes.
DltHub Pro bundles the full lifecycle into one toolbox. I went from “I want GitHub Actions data” to querying validated tables in a single session. Same tool that built the connector also deployed it, will transform it, and can serve a notebook on top of it.
One place from source to data product. One set of credentials to manage. One bill. That’s not convenience, that’s operational sanity.
Actually, what does dltHub Pro NOT have?
…A Docker image you need to run, bulky DAG definitions, and a web UI where you drag boxes around.
No vendor lock-in on the storage layer, to prescribed tools. I brought my own Iceberg catalog (Snowflake Polaris), my own object storage, my own GitHub token. dltHub Pro didn’t ask me to migrate anything or adopt a proprietary format.
It runs in your IDE. It deploys to serverless infrastructure you don’t manage. Your data stays in your lakehouse. If you decide to leave tomorrow, your Iceberg tables are still yours (because they always were).
That’s the entire deployment contract. No orchestrator. No infra-as-code. Just a decorator.
This is exactly where our partnership shines: dltHub Pro handles the agentic ingestion layer, while Tower provides the enterprise lakehouse foundation (the managed Iceberg storage, the Snowflake Polaris catalog integration, and the heavy-duty downstream infrastructure to scale those tables into data products).
Bring your own storage. Bring your own cloud. Keep your own data. dltHub Pro builds the intelligent ingestion services, and Tower scales the lakehouse infrastructure that powers them.
The bottom line
We’re a proud technology partner of dltHub. The movement toward open, composable data stacks isn't a trend, it's an inevitability. If you are tired of wrangling boilerplate and want to get back to delivering real insights, dltHub Pro offers a refreshingly sane path to production.
Ready to see it in action? You can explore the new platform and dive into the documentation over on the dltHub website.
The best part of this open ecosystem is the people building it alongside you. If you have questions about setting up your agentic pipelines or want to swap best practices, the dltHub Slack community is incredibly welcoming and full of experts. And if you want to chat about how Tower runs the infrastructure that powers these modern, scalable data stacks, we would love to have you join the conversation in our Tower Discord community. Let's build the future of data together.