
Serhii Sokolenko
Seven takeaways from seven Iceberg Summit user talks

We attended seven user presentations at the 2025 Iceberg Summit and summarized our takeaways, so you don't have to. We summarized the talks from Airbnb, Bloomberg, Pinterest, Wise, Autodesk, Mediaset (Bauplan), and Slack.
The seven takeaways in a nutshell:
Common reasons for adopting Iceberg are interoperability, cost reduction, support for new use cases
The catalog issue is not settled yet, but everyone agrees that REST catalogs are the future
Data Governance (RLS, CM, and RBAC) is in high demand
There are lots of streaming use cases, but batch is not going anywhere
Streaming Ingestion + Table Maintenance = Operational Complexity
Platform teams are building DevOps-style interfaces (with YAML, PRs, CI/CD) for their users
Data platform teams might be sold on Iceberg, but they now need to convince their client teams
Common reasons for adopting Iceberg are interoperability, cost reduction, new use cases
Speakers mentioned the need for supporting multiple engines (one for querying, one for streaming ingest, another for batch processing, etc.), the potential for saving costs, and the opportunity to support new, near-real-time use cases:
Many: Interoperability with multiple engines (Trino, Spark, Flink, etc.). Everyone had at least three engines that worked on the lakehouse.
Slack: Potential for cost savings due to more efficient streaming ingestion and not copying data around
Slack: Being able to support new use cases that need near-real-time decision-making via streaming ingestion
Bloomberg, Mediaset/Bauplan: Snapshot management and time travel
Bloomberg: Idempotent writes with MERGE allow for clean reruns. Deltas can be applied to historical data.
🟢 Bold prediction: I look forward to reporting about a "unified streaming and batch Iceberg engine" at Iceberg Summit 2026.
Pinterest’s Iceberg use cases

The catalog issue is not settled yet, but everyone agrees that REST catalogs are the future
The catalog layer is where many teams are investing in unlocking features like access control and cross-engine support.
Several users built their own REST-based catalogs backed by Postgres. They did not use the Polaris, Lakekeeper, or Gravitino catalogs that emerged last year. This could be due to the lack of readiness of catalog projects or due to catalog decisions made before the REST standard became widely accepted:
Airbnb: Built a custom catalog to integrate with an internal access system. REST catalog is their choice; they are still evaluating whether or not they need to implement our own or go with one of the open-source catalogs
Bloomberg: Created a REST-compatible catalog using PyIceberg backed by Postgres.
Slack used to use Hive MetaStore and continues using Hive Catalog.
Autodesk uses Hive MetaStore in one data lake and AWS Glue in another.
Bloomberg’s custom REST catalog

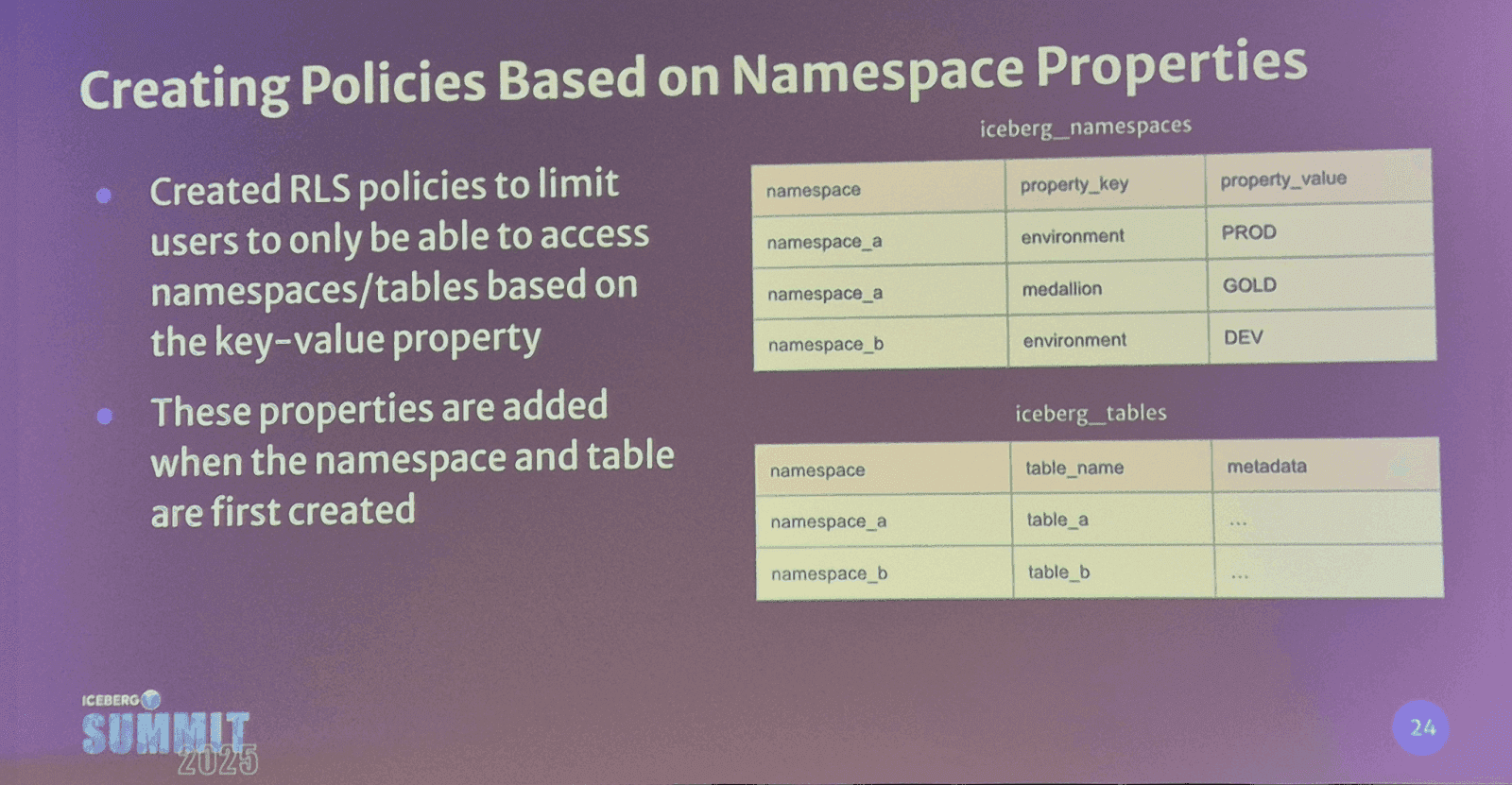
Data Governance (RLS, CM, and RBAC) is in high demand
From the Microsoft panelist to Bloomberg and Autodesk, enterprises want control over data access.
Microsoft VP specifically highlighted Row-level Security (RLS), Column Masking (CM), and Role-based Access Control (RBAC) as enterprise needs.
Bloomberg implemented access control at the table level in their custom-made REST catalog via metadata tags (e.g., users only get a list of tables that they have access to).
Autodesk uses Privacera (but wants OSS alternatives).
Wise is interested in how the "RBAC catalog support in Iceberg" discussion goes.
🟢 Common pain point: security and governance needs are ahead of capabilities in OSS catalogs.
Bloomberg’s catalog policies
Lots of streaming use cases, but batch is not going anywhere
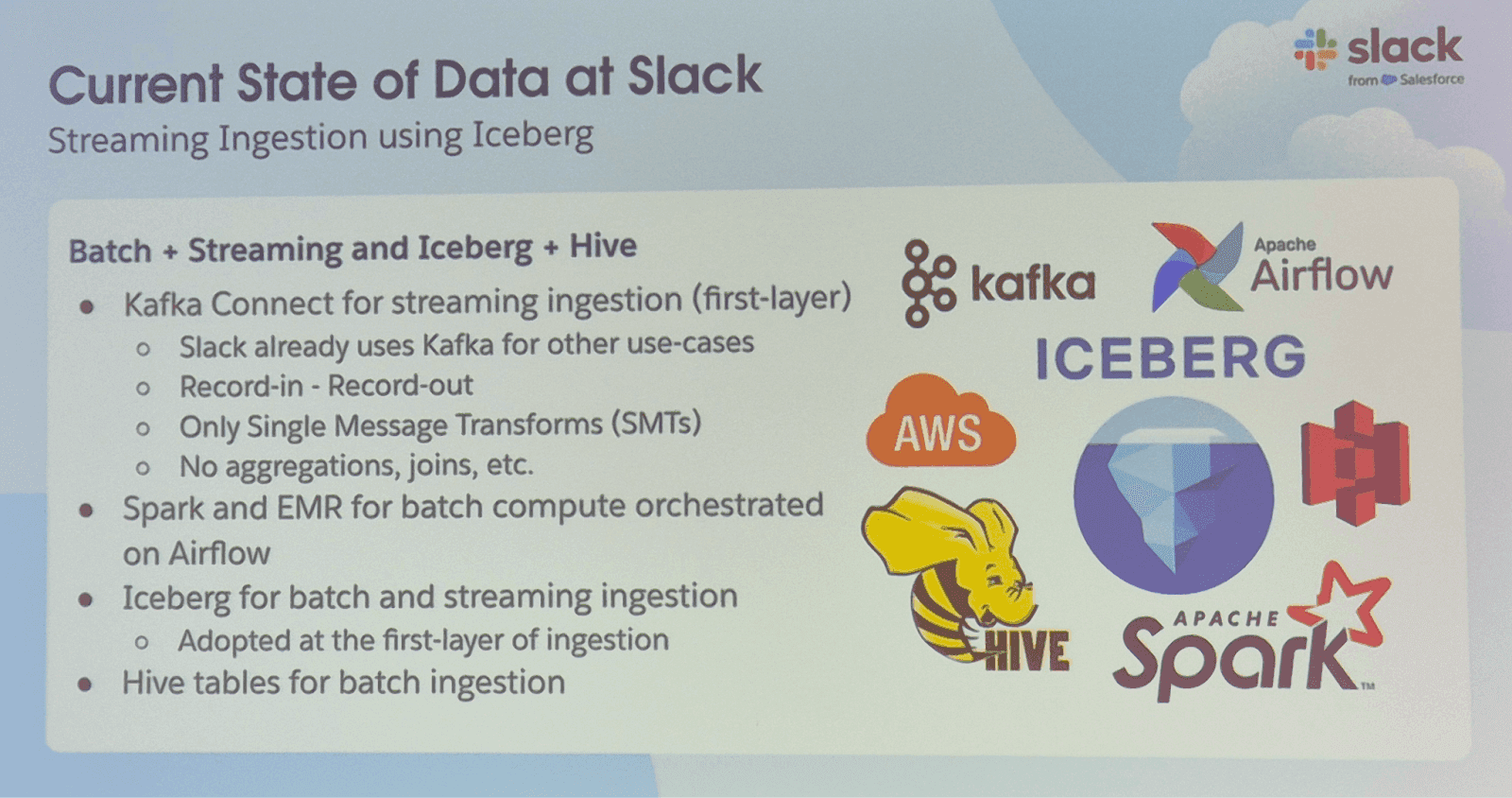
There were many streaming ingestion use cases among digital natives (Airbnb, Pinterest, Wise, Slack) and enterprises (Bloomberg, Autodesk, Mediaset), with events, logs, and CDC records from transactional databases going into the lakehouse. However, batch ingestion and especially batch processing appeared in most environments, too.
This reflects the reality of data processing in companies of all types. Five to seven years ago, customers of traditional analytics vendors like Google, Snowflake, and Databricks saw the expansion of streaming analytics use cases, and the streaming/batch resource consumption split stabilized around 50:50.
The Iceberg ecosystem is reliving that trend today.
Streaming
Slack: Uses streaming ingest to onboard logs, events, and CDC records from transactional DBs into Lakehouse
Wise: Uses Flink to streaming-ingest logs.
Autodesk has both batch and streaming ingestion
Pinterest is using streaming ingestion to get data from SQL Server to Lakehouse
Airbnb: Uses Flink for streaming ingestion, onboards data via CDC, but also has lots of batch ingestion and processing.
Batch
Bloomberg: Moved from a full reprocessing of a 7TB-large table to producing daily increments, still in batch mode.
Bauplan offers small batch and interactive queries.
Current use of Iceberg at Slack
Streaming Ingestion + Table Maintenance = Operational Complexity
A repeating theme is the struggle to balance streaming ingestion with clean, performant tables.
Airbnb: Flink is good for writes but requires extensive table maintenance to achieve good performance for reads; it needs aggressive compaction.
Wise: Had to implement a pretty complex table maintenance in Flink.
Slack: Uses Kafka Connect; suffers from orphan file bloat due to many writers and frequent commits.
🟢 Observation: Everyone is experiencing pain related to streaming ingestion, especially when it comes to cleanup (compaction, orphan files, deletes).
Wise’s custom table maintenance config

Platform teams are building DevOps-style interfaces (with YAML, PRs, CI/CD) for their users
Teams are focused on abstracting complexity and giving users self-serve, low-friction ways to submit jobs to the platform.
Airbnb: Users only need to specify table schema and partitioning; tooling handles the rest.
Wise: Users create a config (in YAML), this goes into a PR, and then it goes into CI/CD
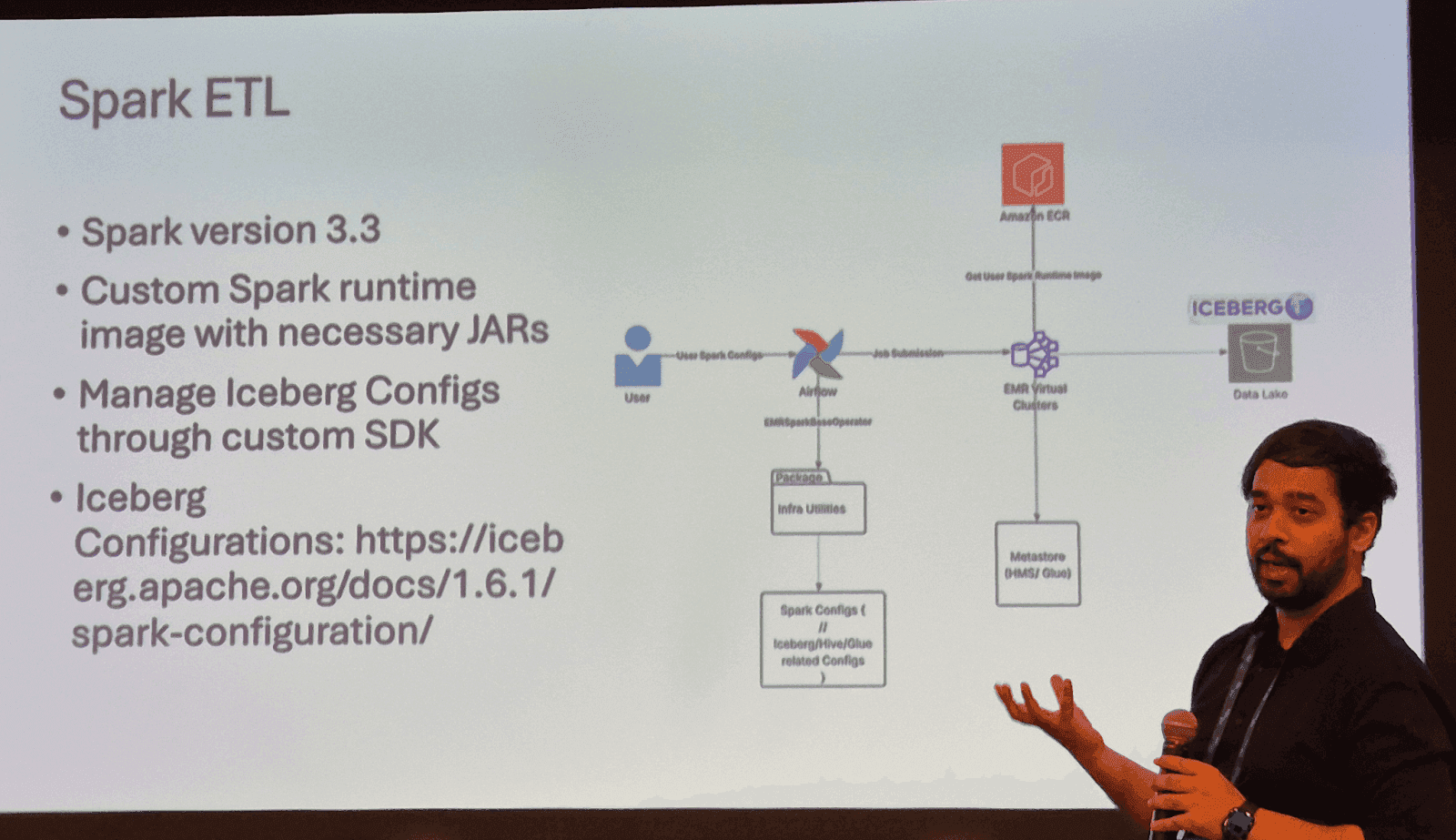
Autodesk: Users submit Spark configs through Airflow, and the platform takes care of the rest (submits the job to the EMR cluster)
Autodesk’s user job submission flow
Data platform teams might be sold on Iceberg, but they now need to convince their client teams
Getting client teams to adopt new lakehouse infrastructure is hard. Strategies include:
Feature Flags (Autodesk): Users can try Hive and Iceberg side-by-side.
Phased Migration (Airbnb): First, get into Iceberg, and then gradually use advanced features.
POC with Renegade Engineers (Mediaset/Bauplan): Bottom-up approach to platform creation.
🟢 Real-world migrations are iterative and require internal champions + UX investment.
Want Help With Migrations to Iceberg?
Tower is a hassle-free platform for data scientists and engineers. We make moving your workloads to Iceberg a breeze. If you want to learn more, contact Tower founders.