
Serhii Sokolenko
Get a GUI for your Iceberg lakehouse with DuckDB UI from Motherduck

We at Tower are big fans of Python as the language of data and AI. We also love Iceberg open storage. We have examples of Python Tower apps reading and writing to Iceberg. We have an internal Iceberg lakehouse, filled with data by Tower apps, that we use to track Tower product metrics. We like to think of it as a little tower built on another tower — very cute.
Once in a while, though, we get the urge to run "SELECT *" on our Iceberg tables. Run it from a GUI, and see the results nicely formatted in a results table below the command. Just like Snowflake, Databricks, BigQuery and countless other tools have trained us to expect from a data tool. Yes, old habits die slowly.
So, we went looking for a SQL-based UI that we could use with an Iceberg lakehouse and asked our favorite developer LLM - Claude.
Claude told us, in a slightly annoyed voice, that "AI will write all the code in 12 months", and "couldn't we just wait a little?"
We waited for a little while but then saw the news that Motherduck had released a UI for DuckDB (thank you, Motherduck!)
Time to give it a go, we thought, because, you know, no more human coding in 12 months!
Setting up the DuckDB UI
The rest of the story unfolded very quickly. Within 30 minutes, we had a GUI running in a browser window and were querying the table in our S3-based lakehouse that we previously created with a Tower job written in Python (blog, GitHub).
Let’s walk through the steps.
1. Install Duckdb if you haven't done so already by running “brew install duckdb”.

Note the time in the screenshot. It was 12:29 when we started.
2. Start the DuckDB UI
3. Figure out how to read an Iceberg table in S3 from the DuckDB UI.
We spent ~25 minutes in this step, but DuckDB's docs were helpful.
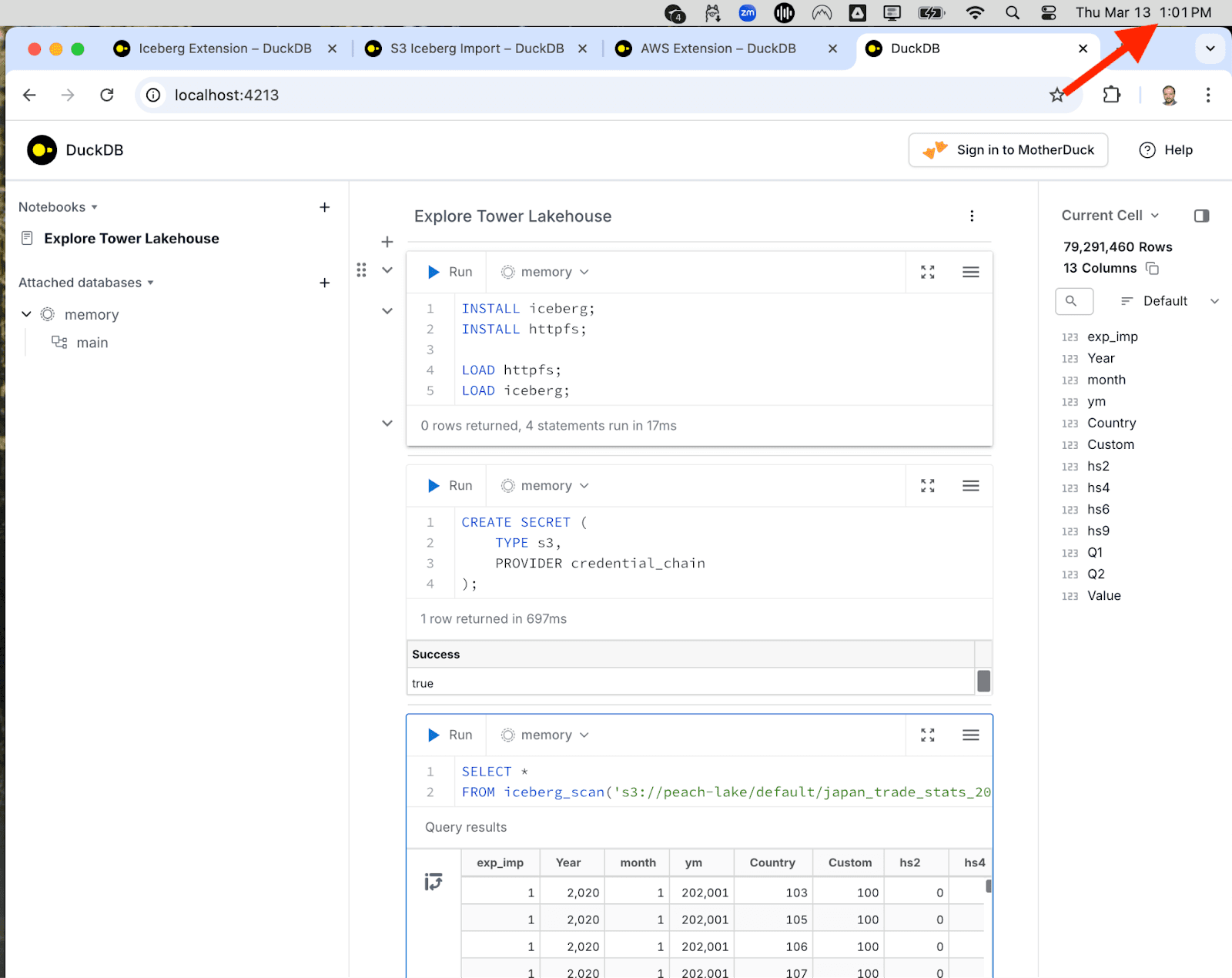
The DuckDB UI has a notebook-like interface with cells where you can type commands.
First, install the extensions that you will need for Iceberg on S3.
Then, set up the credentials to access files in your S3 lakehouse bucket. This is the trickiest part of the whole setup. You should create a DuckDB secret using the credential_chain:
What credentials will the DuckDB UI use to access your lakehouse?
Because you specified the credential_chain provider, the duckdb process you started in the shell will use the same credential-passing mechanism that the aws CLI normally uses.
Let's assume our lakehouse is in the "s3://peach-lake" bucket.
To test if you have access to this bucket, run the following command from the shell:
When you run this command, you should get a list of all files in the lakehouse bucket.
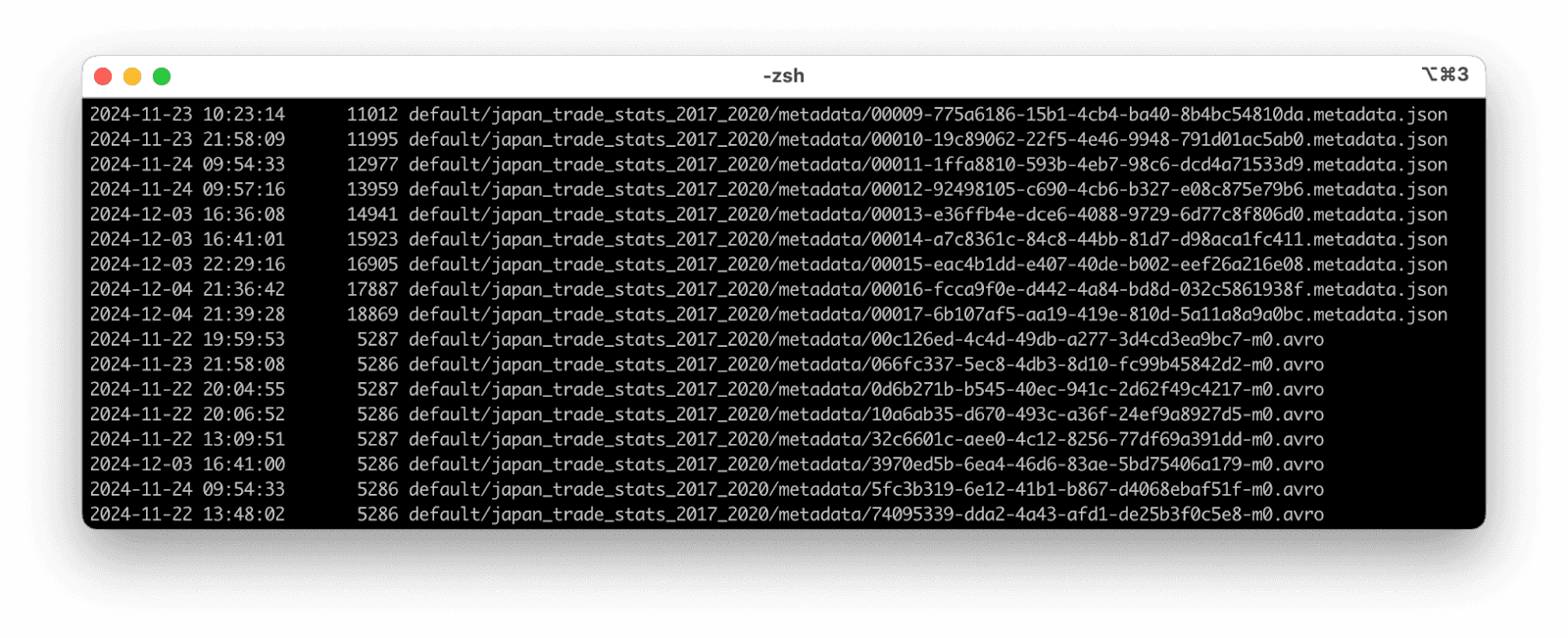
Let’s note the name of the metadata.json file with the highest sequential number in its name.
In our case, it's "00017-6b107af5-aa19-419e-810d-5a11a8a9a0bc.metadata.json".
This is the latest metadata (root) file of our "japan_trade_stats_2017_2020" table, and we will have to use its full path in the SQL query to refer to the table:
Run this query and observe how the DuckDB UI pulls 80 million records from the table into your browser window. Note the time in the upper right corner—1:01 p.m. 32 minutes after installing DuckDB on our laptop we had a graphical UI running that allowed us to query a remote S3-homed lakehouse, just like your favorite cloud data warehouse would.
Improving DuckDB Iceberg integration
Writing the path to the latest Iceberg table metadata file in every SQL statement is not great. Ideally, we would want to refer to our iceberg table by name and write something like:
Or, at the very least, this:
If you run the above command in DuckDB today, you will get back:
Using version-hint is last year’s news, and we are not prepared to do something unsafe. The correct way to determine the latest version of the Iceberg metadata file is to use an Iceberg catalog, preferably a REST-compatible one.
The good news is that the joint DuckDB/Iceberg community is working on the catalog integration as part of the "duckdb-iceberg" extension. If you want to track the issue related to DuckDB Iceberg catalog integration, here is the issue link. Rumor has it that this integration will be released in the next few weeks.
Once that is done (see PR), you will be able to create a special ICEBERG secret to access your catalog, attach your catalog to DuckDB, and access your tables using human-readable syntax, e.g., “SELECT * FROM my_datalake.schema.table” :
Next Steps
Tower loves anything related to Iceberg. If you want to develop data apps that use Iceberg as their lakehouse, contact the Tower founders for a quick demo and an invite code to our private beta.
P.S.
Big Kudos to the Motherduck team for releasing the DuckDB UI!