
Serhii Sokolenko
Build a better open lakehouse with Tower and Lakekeeper

From day one, Tower has been on the lookout for the best Iceberg metadata catalogs, Python SDKs, and related tools. When we evaluated Iceberg REST catalog options, Lakekeeper immediately stood out. The more we learned, the clearer it became that their direction lines up closely with our vision for the future.
Core to our vision is giving developers better data infrastructure. We want to help you avoid the risks of building everything yourself and we use and trust open data tools that we think you will find helpful, too. Lakekeeper from Vakamo is one such tool.
We align with Lakekeeper on many points: we both believe in an open, interoperable ecosystem where data teams retain control over their data and can choose the right tools for the job. It just made sense to bring together Tower’s Python app runtime and orchestration platform with Lakekeeper’s storage management and governance capabilities. We believe this combination will help you build a fully-featured data platform faster with our help.
How Tower works with Lakekeeper
Tower apps can use Lakekeeper to read and write to Iceberg tables using the Tower tables SDK. If you already host a Lakekeeper instance or use their managed service, Tower connects directly to it. Your metadata catalog and governance stay exactly as they are.
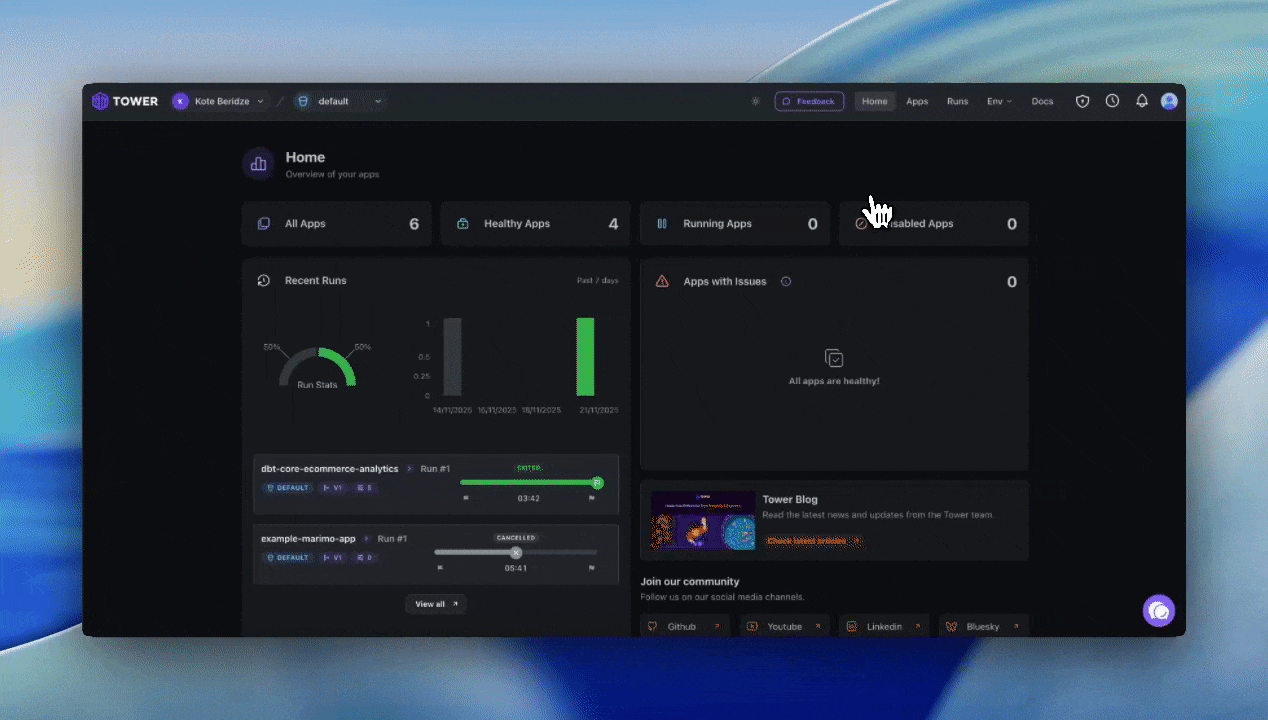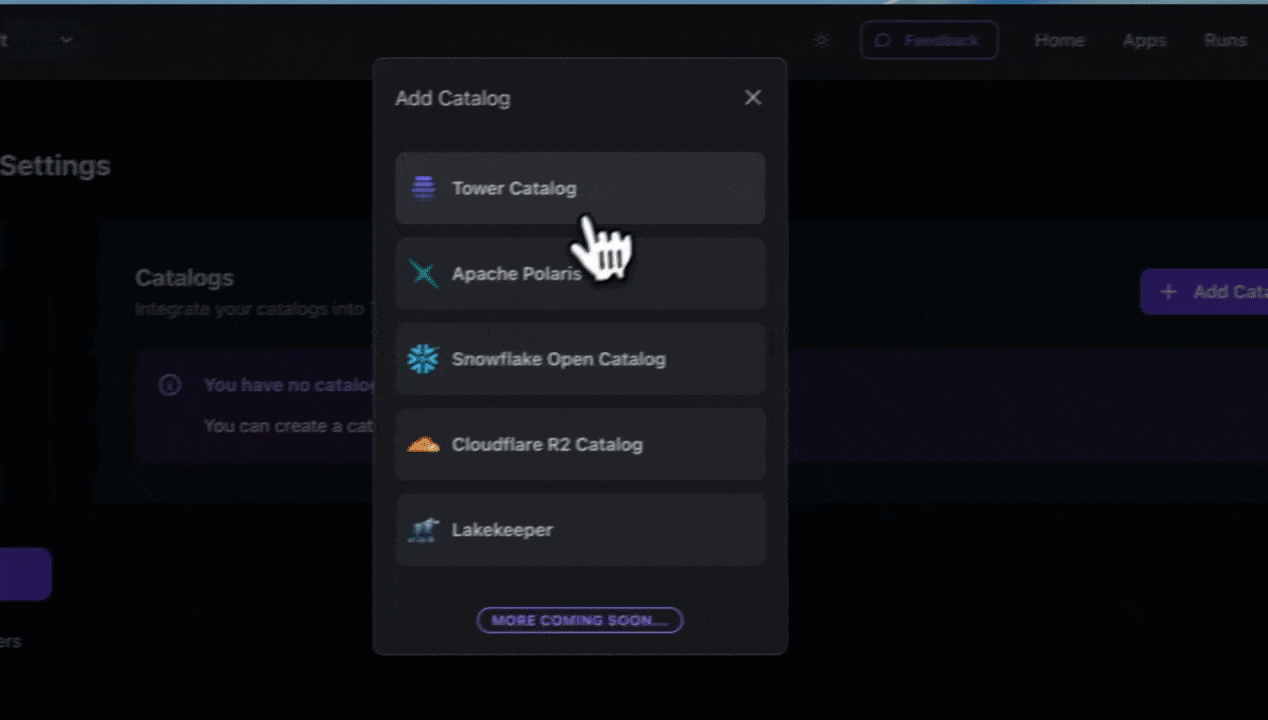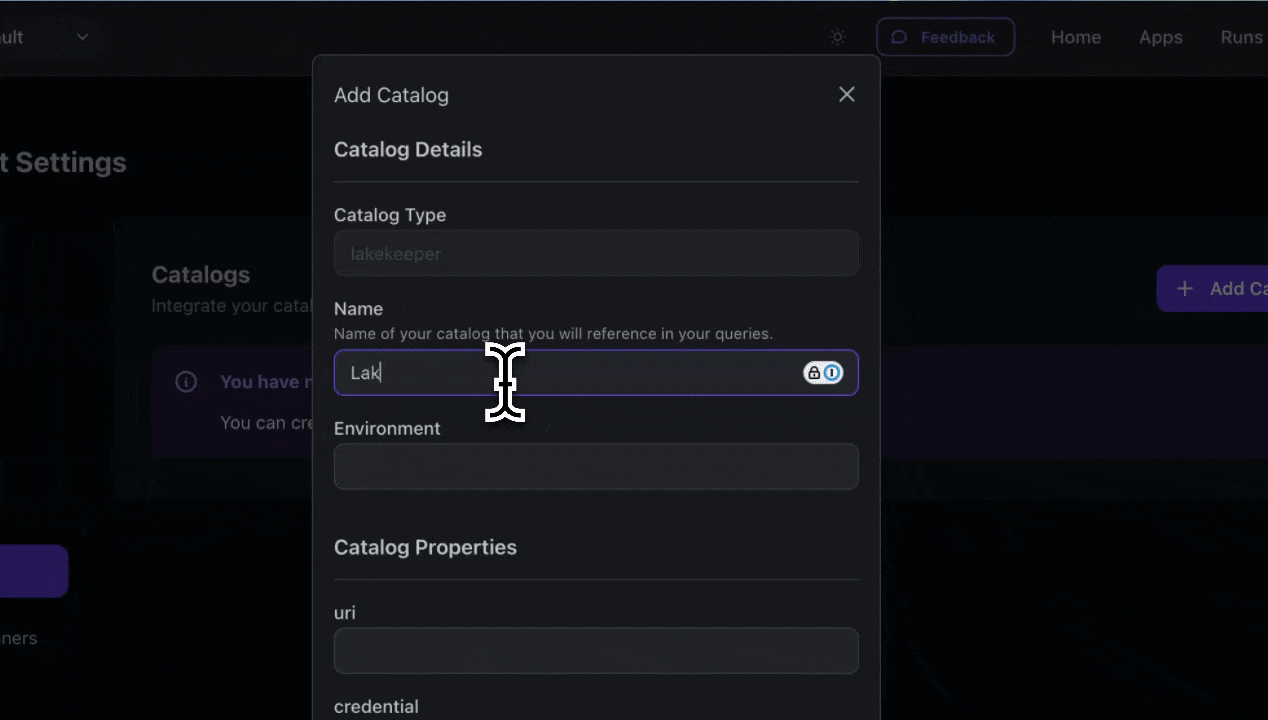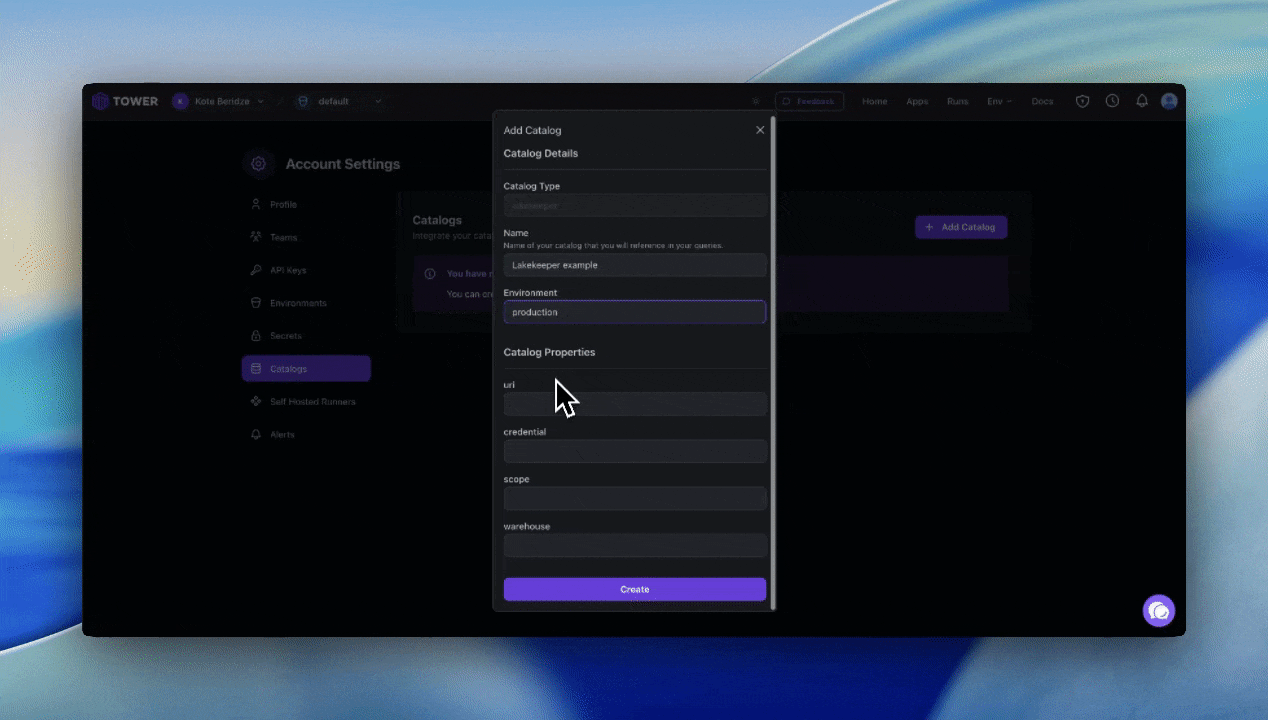
Tower connects to Lakekeeper deployments easily.
Set up your Lakekeeper catalog in Tower.
Enter your credentials.
And that’s it! Try it yourself now on Tower.
What this integration lets you do in Tower
With Lakekeeper connected, you can start using that catalog inside your Tower data apps.
This is how you get a reference to an Iceberg table managed by Lakekeeper.
You can read data from the table using Polars.
You can also delete, insert or upsert records into this table. The entire set of table operations is now available to you!
Start building with Tower and Lakekeeper today
The Tower + Lakekeeper combo gives you the following three advantages:
Build and ship data products faster, with less glue code. Tower runs Python data flows natively, and Lakekeeper provides the governed catalog that supplies them with data.
Governance that’s simple and automated. Lakekeeper’s open REST API keeps policies, lineage, and access rules uniform across your lakehouse, while Tower executes within those rules, giving you reliable compliance without slowing developers down.
Full interoperability and control of your data. Both tools rely on open standards and open APIs, so your data and metadata remain portable and accessible. You get modern lakehouse capabilities without being trapped in any single vendor’s ecosystem.
Connect your Lakekeeper instance to Tower and start building governed data apps on Tower today!